INSPIRE Infrastructure for Spatial Information in Europe
INSPIRE Infrastructure for Spatial Information in Europe
D2.8.III.12 Data Specification on Natural Risk Zones – Technical Guidelines
Title |
D2.8.III.12 Data Specification on Natural Risk Zones – Technical Guidelines |
Creator |
Temporary MIWP 2021-2024 sub-group 2.3.1 |
Date of publication |
2024-01-31 |
Subject |
INSPIRE Data Specification for the spatial data theme Natural Risk Zones |
Publisher |
INSPIRE Maintenance and Implementation Group (MIG) |
Type |
Text |
Description |
This document describes the INSPIRE Data Specification for the spatial data theme Natural Risk Zones |
Format |
AsciiDoc |
Licence |
|
Rights |
Public |
Identifier |
|
Changelog |
https://github.com/INSPIRE-MIF/technical-guidelines/releases/tag/v2024.1 |
Language |
en |
Relation |
Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE) |
Foreword
How to read the document?
This document describes the "INSPIRE data specification on Natural Risk Zones – Technical Guidelines" version 3.0 as developed by the Thematic Working Group (TWG) Natural Risk Zones using both natural and a conceptual schema language.
The data specification is based on a common template[1] used for all data specifications, which has been harmonised using the experience from the development of the Annex I, II and III data specifications.
This document provides guidelines for the implementation of the provisions laid down in the Implementing Rule for spatial data sets and services of the INSPIRE Directive. It also includes additional requirements and recommendations that, although not included in the Implementing Rule, are relevant to guarantee or to increase data interoperability.
Two executive summaries provide a quick overview of the INSPIRE data specification process in general, and the content of the data specification on Natural Risk Zones in particular. We highly recommend that managers, decision makers, and all those new to the INSPIRE process and/or information modelling should read these executive summaries first.
The UML diagrams (in Chapter 5) offer a rapid way to see the main elements of the specifications and their relationships. The definition of the spatial object types, attributes, and relationships are included in the Feature Catalogue (also in Chapter 5). People having thematic expertise but not familiar with UML can fully understand the content of the data model focusing on the Feature Catalogue. Users might also find the Feature Catalogue especially useful to check if it contains the data necessary for the applications that they run. The technical details are expected to be of prime interest to those organisations that are responsible for implementing INSPIRE within the field of Natural Risk Zones, but also to other stakeholders and users of the spatial data infrastructure.
The technical provisions and the underlying concepts are often illustrated by examples. Smaller examples are within the text of the specification, while longer explanatory examples and descriptions of selected use cases are attached in the annexes.
In order to distinguish the INSPIRE spatial data themes from the spatial object types, the INSPIRE spatial data themes are written in italics.
The document will be publicly available as a 'non-paper'. It does not represent an official position of the European Commission, and as such cannot be invoked in the context of legal procedures. |
Legal Notice
Neither the European Commission nor any person acting on behalf of the Commission is responsible for the use which might be made of this publication.
Interoperability of Spatial Data Sets and Services – General Executive Summary
The challenges regarding the lack of availability, quality, organisation, accessibility, and sharing of spatial information are common to a large number of policies and activities and are experienced across the various levels of public authority in Europe. In order to solve these problems it is necessary to take measures of coordination between the users and providers of spatial information. The Directive 2007/2/EC of the European Parliament and of the Council adopted on 14 March 2007 aims at establishing an Infrastructure for Spatial Information in the European Community (INSPIRE) for environmental policies, or policies and activities that have an impact on the environment.
INSPIRE is based on the infrastructures for spatial information that are created and maintained by the Member States. To support the establishment of a European infrastructure, Implementing Rules addressing the following components of the infrastructure have been specified: metadata, interoperability of spatial data sets (as described in Annexes I, II, III of the Directive) and spatial data services, network services, data and service sharing, and monitoring and reporting procedures.
INSPIRE does not require collection of new data. However, after the period specified in the Directive[2] Member States have to make their data available according to the Implementing Rules.
Interoperability in INSPIRE means the possibility to combine spatial data and services from different sources across the European Community in a consistent way without involving specific efforts of humans or machines. It is important to note that "interoperability" is understood as providing access to spatial data sets through network services, typically via Internet. Interoperability may be achieved by either changing (harmonising) and storing existing data sets or transforming them via services for publication in the INSPIRE infrastructure. It is expected that users will spend less time and efforts on understanding and integrating data when they build their applications based on data delivered in accordance with INSPIRE.
In order to benefit from the endeavours of international standardisation bodies and organisations established under international law their standards and technical means have been utilised and referenced, whenever possible.
To facilitate the implementation of INSPIRE, it is important that all stakeholders have the opportunity to participate in specification and development. For this reason, the Commission has put in place a consensus building process involving data users, and providers together with representatives of industry, research and government. These stakeholders, organised through Spatial Data Interest Communities (SDIC) and Legally Mandated Organisations (LMO)[3], have provided reference materials, participated in the user requirement and technical[4] surveys, proposed experts for the Data Specification Drafting Team[5], the Thematic Working Groups[6] and other ad-hoc cross-thematic technical groups and participated in the public stakeholder consultations on draft versions of the data specifications. These consultations covered expert reviews as well as feasibility and fitness-for-purpose testing of the data specifications[7].
This open and participatory approach was successfully used during the development of the data specifications on Annex I, II and III data themes as well as during the preparation of the Implementing Rule on Interoperability of Spatial Data Sets and Services[8] for Annex I spatial data themes and of its amendment regarding the themes of Annex II and III.
The development framework elaborated by the Data Specification Drafting Team aims at keeping the data specifications of the different themes coherent. It summarises the methodology to be used for the development of the data specifications, providing a coherent set of requirements and recommendations to achieve interoperability. The pillars of the framework are the following technical documents[9]:
-
The Definition of Annex Themes and Scope describes in greater detail the spatial data themes defined in the Directive, and thus provides a sound starting point for the thematic aspects of the data specification development.
-
The Generic Conceptual Model defines the elements necessary for interoperability and data harmonisation including cross-theme issues. It specifies requirements and recommendations with regard to data specification elements of common use, like the spatial and temporal schema, unique identifier management, object referencing, some common code lists, etc. Those requirements of the Generic Conceptual Model that are directly implementable are included in the Implementing Rule on Interoperability of Spatial Data Sets and Services.
-
The Methodology for the Development of Data Specifications defines a repeatable methodology. It describes how to arrive from user requirements to a data specification through a number of steps including use-case development, initial specification development and analysis of analogies and gaps for further specification refinement.
-
The Guidelines for the Encoding of Spatial Data defines how geographic information can be encoded to enable transfer processes between the systems of the data providers in the Member States. Even though it does not specify a mandatory encoding rule it sets GML (ISO 19136) as the default encoding for INSPIRE.
-
The Guidelines for the use of Observations & Measurements and Sensor Web Enablement-related standards in INSPIRE Annex II and III data specification development provides guidelines on how the "Observations and Measurements" standard (ISO 19156) is to be used within INSPIRE.
-
The Common data models are a set of documents that specify data models that are referenced by a number of different data specifications. These documents include generic data models for networks, coverages and activity complexes.
The structure of the data specifications is based on the "ISO 19131 Geographic information - Data product specifications" standard. They include the technical documentation of the application schema, the spatial object types with their properties, and other specifics of the spatial data themes using natural language as well as a formal conceptual schema language[10].
A consolidated model repository, feature concept dictionary, and glossary are being maintained to support the consistent specification development and potential further reuse of specification elements. The consolidated model consists of the harmonised models of the relevant standards from the ISO 19100 series, the INSPIRE Generic Conceptual Model, and the application schemas[11] developed for each spatial data theme. The multilingual INSPIRE Feature Concept Dictionary contains the definition and description of the INSPIRE themes together with the definition of the spatial object types present in the specification. The INSPIRE Glossary defines all the terms (beyond the spatial object types) necessary for understanding the INSPIRE documentation including the terminology of other components (metadata, network services, data sharing, and monitoring).
By listing a number of requirements and making the necessary recommendations, the data specifications enable full system interoperability across the Member States, within the scope of the application areas targeted by the Directive. The data specifications (in their version 3.0) are published as technical guidelines and provide the basis for the content of the Implementing Rule on Interoperability of Spatial Data Sets and Services[12]. The content of the Implementing Rule is extracted from the data specifications, considering short- and medium-term feasibility as well as cost-benefit considerations. The requirements included in the Implementing Rule are legally binding for the Member States according to the timeline specified in the INSPIRE Directive.
In addition to providing a basis for the interoperability of spatial data in INSPIRE, the data specification development framework and the thematic data specifications can be reused in other environments at local, regional, national and global level contributing to improvements in the coherence and interoperability of data in spatial data infrastructures.
Natural Risk Zones – Executive Summary
This document contains the data specification on INSPIRE Annex III spatial data theme 12, Natural Risk Zones. This specification is the work of the Natural Risk Zones thematic working group (TWG-NZ)- a multinational team of experts volunteered from the community of SDICs (Spatial Data Interest Communities) and LMOs (Legally Mandated Organisations) of INSPIRE.
Using the latest research and experience available, TWG-NZ has defined Natural Risk Zones as areas where natural hazards are coincident with populated areas and/or areas of particular environmental/ cultural or economic value. Risk in this context is defined as:
Risk = Hazard x Exposure x Vulnerability
of human health, the environmental, cultural and economic assets in the zone considered.
Precise definitions of these widely used terms (see Chapter 2.1) as well as a clear distinction between "hazard" and "risk" is essential for understanding of this data specification.
The domain of the Natural Risk Zones data specification is potentially very large, it encompasses hazards from floods to geomagnetic storms, and exposed elements from buildings to designated environmental features this is described further in Chapter 2 of this report.
The data and information that is included in this data specification take as a starting point the existence of the delineation of a hazard area. For some hazards, for example meteorological hazards it is not straight forward to delineate concrete hazard areas as occurrence depends on complex, respectively chaotic meteorological conditions. Source data for each hazard are mostly in the domain of other INSPIRE Annex I, II and III themes for example fault lines as a source for earthquakes, in the Geology theme. As a consequence, this data specification does not include the modelling of the processes and scientific methods that were used in the delineation of hazard areas.
The approach taken to model Natural Risk Zones is generic in its treatment of each of hazard, exposure, vulnerability and risk, but five use cases have been created to demonstrate the fit of the model with specific examples for different types of hazard:
-
Floods (calculation of flood impact, reporting and flood hazard/risk mapping)
-
Risk Management Scenario (an example from a national perspective)
-
Landslides (hazard mapping, vulnerability assessment and risk assessment)
-
Forest fires (danger, vulnerability and risk mapping)
-
Earthquake insurance
These use cases are listed in Annex B.
The case of flood hazard has also been used to demonstrate the capacity for extension of the model where a requirement to be more specific exists (see Annex D). Flood risk is significantly more precisely defined than other hazards, due in part to the development of the Floods Directive (2007/60/EC - FD) and collaboration with the relevant (FD) expert group.
The data specification includes modelling of risk zones caused by natural phenomena – primarily. Nevertheless, it is anticipated that the core of the model may be valid for the modelling of other types of hazards beyond the immediate domain of the Natural Risk Zones specification.
In the real world, hazards can be single, sequential or combined in their origin and effects. There are complexities in adequately modelling these circumstances that complicate the communication of good practice in modelling more simple hazard and risk relationships. At this time the Natural Risk Zones data model has not been designed so that it could also operate in multi-risk circumstances.
The model includes measured past events and modelled future events. It does not deal with real-time data and respectively events as they are happening. This is the domain of monitoring and emergency response which is largely out of the domain of Natural Risk Zones.
Natural Risk Zones also involve significant engagement with other thematic areas from INSPIRE. This involvement stems from the nature of hazard, exposure, vulnerability and risk as defined in this document. Several other thematic areas will input attributes vital to understanding the nature of hazard, yet others are vital in the understanding of exposure while others model the monitoring of hazard areas.
The concepts included in the model are abstract and can be specialised using either vector or coverage spatial representation. This is done in order to create a framework which enables exchange of data that are either vector or coverage, considering that any of the spatial objects can be modelled in either way.
There are 4 key spatial object types that are modelled;
-
Hazard area
-
Observed event
-
Risk zone
-
Exposed element
While preparing the data specification, three primary categories of natural risk zone data provider have been identified:
-
Natural hazards data providers (past event registers and/or modelled hazards)
-
Vulnerability data providers (including exposure information)
-
Risk data providers
It is important for all potential users of natural risk zones information to know which hazard is causing a particular risk zone. It is crucial for the mitigation and management of the risk. For that reason, any provider should identify which type of natural hazard their data is related to; and for vulnerability data providers, which kind of exposed element is at risk.
In order to facilitate semantic interoperability, this data specification includes a simple, high level classification through two code lists providing type of natural hazards and type of exposed element categorizations. These code lists are not meant to be exhaustive, but can be extended with narrower terms by Member States. Moreover, data providers can add a more specific classification for both concepts.
One of the main purposes of hazard and risk maps is to inform clearly thus supporting effective communication between modellers, data providers, policy makers and the citizen. We hope that this data specification can play a part in improving this communication.
Acknowledgements
Many individuals and organisations have contributed to the development of these Guidelines.
Building this model has not been a trivial undertaking, Thematic Working Group Natural Risk Zones (TWG-NZ) has received significant contributions from the community of SDICs and LMOs related to the Natural Risk Zones domain. We have also benefited from the expertise of many individuals and the continued support of each of our employers. We would like to thank all of these for their generosity and support in completing this piece of work.
For the final version of the Technical Guidelines document the TWG-NZ included:
Matthew Harrison (TWG Facilitator), Florian Thomas (TWG Editor), José I. Barredo, Venco Bojilov, Raquel Canet Castella, Otakar Cerba, George Exadaktylos, Miguel Llorente Isidro, Manuela Pfeiffer, Robert Tomas (European Commission contact point).
Cristiano Giovando and Andrea Camia also contributed to earlier drafts.
Other contributors to the INSPIRE data specifications are the Drafting Team Data Specifications, the JRC Data Specifications Team and the INSPIRE stakeholders - Spatial Data Interested Communities (SDICs) and Legally Mandated Organisations (LMOs).
Contact information
Maria Vanda Nunes de Lima & Michael Lutz
European Commission Joint Research Centre (JRC)
Institute for Environment and Sustainability
Unit H06: Digital Earth and Reference Data
http://inspire.ec.europa.eu/index.cfm/pageid/2
Table of contents
- 1. Scope
- 2. Overview
- 3. Specification scopes
- 4. Identification information
- 5. Data content and structure
- 5.1. Application schemas – Overview
- 5.2. Basic notions
- 5.3. Application schema NaturalRiskZones
- 5.3.1. Description
- 5.3.2. Feature catalogue
- 5.3.2.1. Spatial object types
- 5.3.2.1.1. AbstractExposedElement
- 5.3.2.1.2. AbstractHazardArea
- 5.3.2.1.3. AbstractObservedEvent
- 5.3.2.1.4. AbstractRiskZone
- 5.3.2.1.5. ExposedElementCoverage
- 5.3.2.1.6. HazardCoverage
- 5.3.2.1.7. ObservedEventCoverage
- 5.3.2.1.8. RiskCoverage
- 5.3.2.1.9. ObservedEvent
- 5.3.2.1.10. HazardArea
- 5.3.2.1.11. RiskZone
- 5.3.2.1.12. ExposedElement
- 5.3.2.2. Data types
- 5.3.2.3. Code lists
- 5.3.2.4. Imported types (informative)
- 5.3.2.4.1. AbstractFeature
- 5.3.2.4.2. CharacterString
- 5.3.2.4.3. CoverageByDomainAndRange
- 5.3.2.4.4. DateTime
- 5.3.2.4.5. DocumentCitation
- 5.3.2.4.6. EnvironmentalMonitoringProgramme
- 5.3.2.4.7. GM_Object
- 5.3.2.4.8. GM_Surface
- 5.3.2.4.9. Identifier
- 5.3.2.4.10. Measure
- 5.3.2.4.11. Number
- 5.3.2.4.12. Probability
- 5.3.2.4.13. TM_Period
- 5.3.2.1. Spatial object types
- 6. Reference systems, units of measure and grids
- 7. Data quality
- 8. Dataset-level metadata
- 9. Delivery
- 10. Data Capture
- 11. Portrayal
- Bibliography
- Annex A: Abstract Test Suite - (normative)
- A.1. Application Schema Conformance Class
- A.1.1. Schema element denomination test
- A.1.2. Value type test
- A.1.3. Value test
- A.1.4. Attributes/associations completeness test
- A.1.5. Abstract spatial object test
- A.1.6. Constraints test
- A.1.7. Geometry representation test
- A.1.8. Risk zone – theme specific test 1
- A.1.9. Risk zone – theme specific test 2
- A.2. Reference Systems Conformance Class
- A.3. Data Consistency Conformance Class
- A.4. Metadata IR Conformance Class
- A.5. Information Accessibility Conformance Class
- A.6. Data Delivery Conformance Class
- A.7. Portrayal Conformance Class
- A.8. Technical Guideline Conformance Class
- A.8.1. Multiplicity test
- A.8.2. CRS http URI test
- A.8.3. Metadata encoding schema validation test
- A.8.4. Metadata occurrence test
- A.8.5. Metadata consistency test
- A.8.6. Encoding schema validation test
- A.8.7. Coverage multipart representation test
- A.8.8. Coverage domain consistency test
- A.8.9. Style test
- A.1. Application Schema Conformance Class
- Annex B: Use cases - (informative)
- Annex C: Code list value - (normative)
- Annex D: The Natural Risk Zones extension for Floods Directive - (informative)
1. Scope
This document specifies a harmonised data specification for the spatial data theme Natural Risk Zones as defined in Annex III of the INSPIRE Directive.
This data specification provides the basis for the drafting of Implementing Rules according to Article 7 (1) of the INSPIRE Directive [Directive 2007/2/EC]. The entire data specification is published as implementation guidelines accompanying these Implementing Rules.
2. Overview
2.1. Name
INSPIRE data specification for the theme Natural Risk Zones.
2.2. Informal description
Definition:
Vulnerable areas characterised according to natural hazards (all atmospheric, hydrologic, seismic, volcanic and wildfire phenomena that, because of their location, severity, and frequency, have the potential to seriously affect society) e.g. floods, landslides and subsidence, avalanches, forest fires, earthquakes, volcanic eruptions. [Directive 2007/2/EC]
Description:
Natural Risk Zones are zones where natural hazard areas are coincident with highly populated areas and/or areas of particular environmental, cultural, or economic value. Risk in this context is defined as:
Risk = Hazard x Exposure x Vulnerability
of human health, the environmental, cultural and economic assets in the zone considered.
R = H * E * V
This leads to the expression of risk in terms such as:
"For example this leads to a hazard of flood with a return period of 100 years with and exposed element of 100 houses and those houses are 100% vulnerable to floods: Every year there is a 1% chance of having 100 houses destroyed due to floods of a given magnitude".
Or
"For example this leads to a hazard of forest fire with a return period of 5 years with 25 houses exposed leading to: On average, five houses are destroyed every year due to forest fire of a given magnitude".
The definition of each of these terms in the risk function almost has a discipline of their own. For the purposes of the TWG-NZ it was decided to adopt the existing, yet specific definitions below.
Risk (R)
Risk is the combination of the consequences of an event (hazard) and the associated likelihood/probability of its occurrence, (ISO 31010).
Comment: This definition closely follows the definition of the ISO/IEC Guide 73. The word "risk" has two distinctive connotations: in popular usage the emphasis is usually placed on the concept of chance or possibility, such as in "the risk of an accident"; whereas in technical settings the emphasis is usually placed on the consequences, in terms of "potential losses" for some particular cause, place and period. It can be noted that people do not necessarily share the same perceptions of the significance and underlying causes of different risks, (UNISDR 2009).
Hazard (H)
A dangerous phenomenon, substance, human activity or condition that may cause loss of life, injury or other health impacts, property damage, loss of livelihoods and services, social and economic disruption, or environmental damage, (UNISDR 2009).
Comment: The hazards of concern to disaster risk reduction as stated in footnote 3 of the Hyogo Framework are "… hazards of natural origin and related environmental and technological hazards and risks." Such hazards arise from a variety of geological, meteorological, hydrological, oceanic, biological, and technological sources, sometimes acting in combination. In technical settings, hazards are described quantitatively by the likely frequency of occurrence of different intensities for different areas, as determined from historical data or scientific analysis (UNISDR2009).
Remark: Technological hazards were not considered for this data specification (cf. page 16).
Exposure (E)
People, property, systems, or other elements present in hazard zones that are thereby subject to potential losses, (UNISDR 2009).
Vulnerability (V)
The characteristics and circumstances of a community, system or asset, that makes it susceptible to the damaging effects of a hazard, (UNISDR 2009).
Comment: There are many aspects of vulnerability, arising from various physical, social, economic, and environmental factors. Examples may include poor design and construction of buildings, inadequate protection of assets, lack of public information and awareness, limited official recognition of risks and preparedness measures, and disregard for wise environmental management. Vulnerability varies significantly within a community and over time. This definition identifies vulnerability as a characteristic of the element of interest (community, system or asset) which is independent of its exposure. However, in common use the word is often used more broadly to include the element’s exposure UNISDR (2009).
One of the reasons for the difficulty in terminology is that the language of risk has developed across a broad range of disciplines, including those beyond the scope of this thematic working group, including financial risk, disaster management etc. Figure 1 demonstrates the relationship between the various concepts defined above in a spatial context. Figure 2 shows this as a more abstract conceptual model.
Some of the confusion arises from the differing use of language when both specialists and non-specialists are talking about the concept of risk. Vulnerability and exposure are the terms most frequently interchanged. The terms used in the model follow the UNISDR2009 definitions and more recently the "Risk Assessment and Mapping Guidelines for Disaster Management" document of the Council of the European Union.
In the insurance industry risks are referred to using the term "Perils". This sector are large users of Public Sector hazard, risk and vulnerability information and are a significant part of an international risk management framework that will benefit from this data specification whilst bearing in mind that INSPIRE Directive first applies to data-holding public authorities or those acting on their behalf. This data specification outlines spatial information which could be the subject of public private partnerships between data-holding public authorities and the insurance industry.
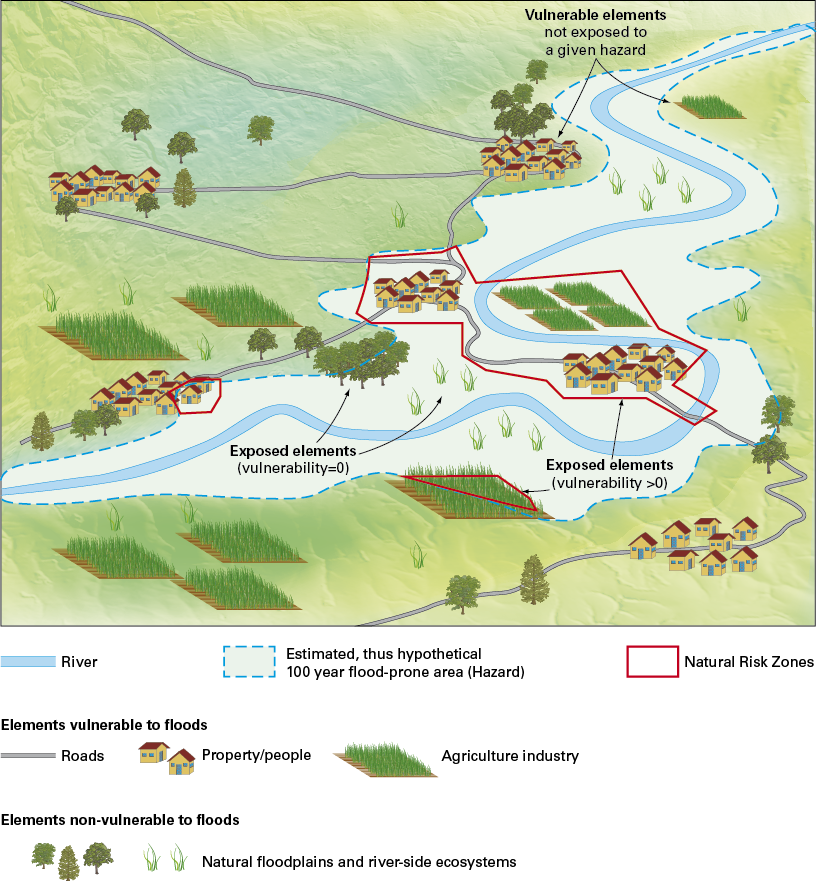
Figure 1: Main concepts in the Natural Risk Zones model.
As another example of the wider use of natural risk zones information, the EU Structural Eurocodes or Eurocodes are the current building standards for Europe, published by the European Committee for Standardization. Eurocode 1, for example, considers fire action on building structures, whereas Eurocode 8 refers to earthquake resistant buildings. So it is important always to associate "vulnerability" assessment of building structures with the application or not of Eurocodes. In order to make an assessment as of whether an "exposed" engineering structure (exposed element) is also "vulnerable" and "how vulnerable it is" (i.e. a specific assessment) to a given hazard (e.g. flood, fire, landslide etc) one should know the design and construction (or retrofitting) characteristics of this particular structure as well as if a design is based on a standard or code of practice. For example if a building or retaining wall is made from fire resistant materials, then it is less vulnerable to a fire, or if a building is earthquake resistant, it is not expected to suffer serious damages in an earthquake of a given magnitude, unlike another building that has been constructed without special consideration to earthquakes.
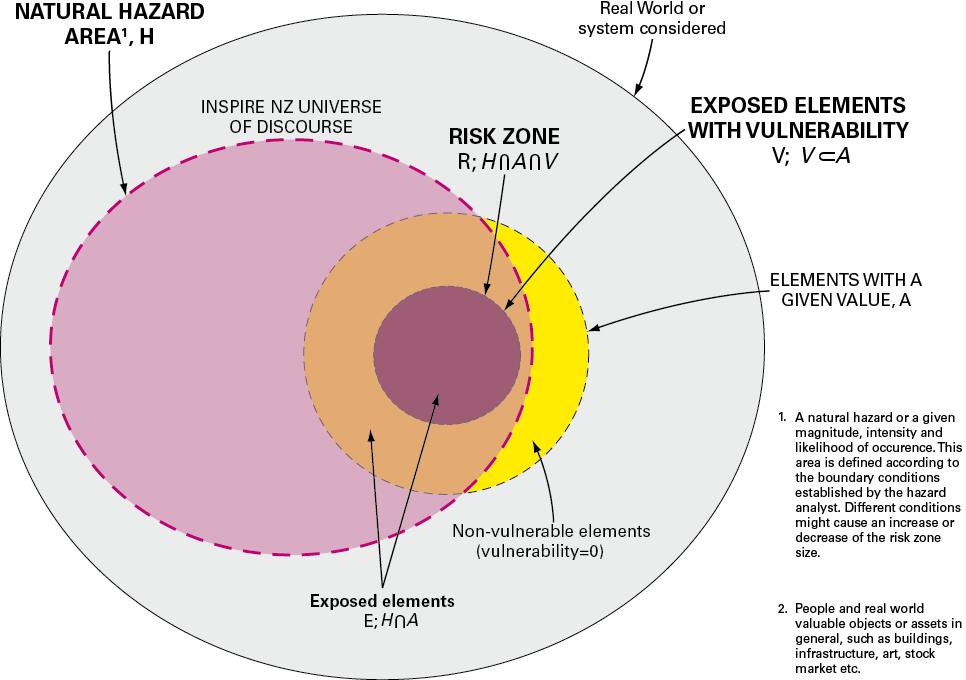
Figure 2: Alternative diagram to show the main concepts in the Natural Risk Zones model
Natural Risk Zones thematic area
This data specification is meant to be as useful and usable as possible for the purposes of data interoperability. As such the data model has been developed to be relevant to the public data and information that is already available. In many cases this is only susceptibility or hazard or vulnerability. It is foreseen that even in the absence of a full risk model it is still possible to share data and information to a common specification about hazards that have the potential to affect people, property and services and the environment across Europe.
It is important for all potential users of natural risk zones information to know what hazard is causing a particular risk zone. It is crucial especially for the mitigation and management of the risk. Therefore, the data and information that are included in this data specification conceptually considers the existence of the delineation of a hazard area as the most important object providing the backbone of the data model. Exposed elements, risk zones and observed past events are also conceptually joined through the hazard and risk delineation process. Source data for the delineation of each hazard are mostly in within the remit of other INSPIRE thematic areas, e.g. fault lines as a source for earthquakes (Annex II Geology). As a consequence, this data specification does not include those nor the modelling of the processes and scientific methods that were used in the identification of hazard areas.
The data specification includes modelling of natural hazards caused by natural phenomena - primarily. It is anticipated that for instance some types of technological hazards could precipitate natural hazards (and vice versa), in which case the model is likely to remain valid as causative factors are not modelled. It is also true that the core of the model may be valid for the modelling of other hazards beyond the Natural Risk Zones specification. The model has not been designed with these in mind but may be useful in these circumstances.
Many hazards are sudden in their nature. However, several categories of natural hazards with major impacts on civil contingency and on environmental/cultural and economic assets are not sudden in nature. They may be permanent phenomena going unnoticed by the population (e.g. radon gas emissions or the deficit or excess of elements in soil, or slow phenomena such as slow ground motion). These hazardous processes are considered within the model. All other natural processes that have no negative potential impact in a human activity are not considered.
In the real world, past hazardous events can been seen as single natural processes, sequential or combined in their origin and effects. Modelling these circumstances complicates the communication of good scientific practice in modelling hazard and risk relationships. The current data model is not designed so that it could also operate in multi-risk or multi-hazard circumstances.
Even though the data model includes measured past events relevant for the understanding of future events, it does not deal with real-time events as they are happening, which is in the domain of monitoring and emergency response, nor does it include disaster databases.
The core data model is extensible in many directions, to cover many domain specific requirements. Based on the expertise in the TWG–NZ and collaboration with relevant Floods Directive (FD) group a Floods extension example was developed to demonstrate how the domain specific requirements can be modelled using the INSPIRE NZ core data model. In Annex D there is also a mapping of feature types between the Natural Risk Zones data specification and the draft Flood hazard/risk mapping feature types (FD).
Given that there are so many approaches, models and means of the delineation of natural risk zones, and provided that a common practice is using both coverage and vector data types, both coverage and vector data are addressed in this data specification.
There are no definitive- widely accepted - sources of pan-European natural hazard classification; however there are several classifications dealing with disasters. The Munich Re and CRED (Centre of Research on the Epidemiology of Disasters) disaster database classification has been identified as a commonly used classification, but has not been used here as it deals with the collection of disaster information. As a result the thematic working group has agreed on a very high level simple and extensible hazard type classification, that in the model is supplemented with a possibility to provide an additional classification term that addresses e.g. more detailed or local specifics of a hazard type. Whilst the proposed hazard classification is by no means exhaustive, the group feels that this approach is representative and by considering the hazards identified there, much of the range of hazards considered to be in the thematic area will have been covered. However the provision of more detailed hazard types is highly recommended.
In summary, TWG-NZ has considered:
-
A generic approach to all natural hazards
-
A generic approach to all natural risk zones
-
Only the most relevant associated data
-
Modelled hazards
-
Observed events
-
Data that can be of coverage or vector type
TWG-NZ has not primarily considered:
-
Real time data
-
Technological hazards
-
Multi-hazard/risks
-
Modelling of the processes and scientific methods or data used to define hazard areas, exposed elements and risk zones
-
Disaster management
Links to other thematic working groups
Exposed elements
Knowledge about elements exposed to a specific hazard is also of utmost importance. So assessment of the level of threat that a certain hazard (flood, landslide, forest fire, etc.) poses to life, health, property or environment should be conducted. Here, data and services about settlements, infrastructure, land use and many others will be needed and provided by the other Annex I, II and III data themes. Examples of these would include but not be limited to: Buildings, Transport networks, Land use, Industrial and production facilities, Agricultural and Aqua-cultural facilities, Utility and Governmental Services. The list is not and cannot be exhaustive, as it has been decided to have a generic approach. In order to define this, the model uses a link between "Exposed element" and the abstract GML feature type. The abstract GML feature type encompasses all feature types that can be provided under INSPIRE.
Environmental monitoring program
Because in some cases monitoring natural phenomena is key to the process of managing the risk zones, a link with the Environmental Monitoring Facilities data model is made.
Examples of Use
This section describes identified users of spatial information about natural hazards and risks as requested by the interest groups that responded through the User Requirement Survey. The NZ Core-data model covers a generic approach with the option to extend the model for specific hazards/risks. Further, more detailed examples - Use cases are given in Annex B. The most elaborated example – mapping is described in a form of an Data model Extension in Annex D.
The different kinds of users and uses may be grouped;
-
Risk analysts, for the assessment of natural risks and mapping of areas prone to be hit by hazards;
-
Public safety planners, for the long term regulation and management of land and activities;
-
Disaster managers, for disaster response and emergency operations as preliminary hazard or risk input;
-
Policy makers for overall policy development, reporting and trend analysis, commonly at national and international level;
-
Insurance and reinsurance for disaster preparedness;
-
The general public for citizen awareness.
Definition: |
2.3. Normative References
[Directive 2007/2/EC] Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE)
[Directive 2007/60/EC] Directive of the European Parliament and of the Council of 23 October 2007 on the assessment and management of flood risks
[ISO 19107] EN ISO 19107:2005, Geographic Information – Spatial Schema
[ISO 19108] EN ISO 19108:2005, Geographic Information – Temporal Schema
[ISO 19108-c] ISO 19108:2002/Cor 1:2006, Geographic Information – Temporal Schema, Technical Corrigendum 1
[ISO 19111] EN ISO 19111:2007 Geographic information - Spatial referencing by coordinates (ISO 19111:2007)
[ISO 19113] EN ISO 19113:2005, Geographic Information – Quality principles
[ISO 19115] EN ISO 19115:2005, Geographic information – Metadata (ISO 19115:2003)
[ISO 19118] EN ISO 19118:2006, Geographic information – Encoding (ISO 19118:2005)
[ISO 19123] EN ISO 19123:2007, Geographic Information – Schema for coverage geometry and functions
[ISO 19125-1] EN ISO 19125-1:2004, Geographic Information – Simple feature access – Part 1: Common architecture
[ISO 19135] EN ISO 19135:2007 Geographic information – Procedures for item registration (ISO 19135:2005)
[ISO 19138] ISO/TS 19138:2006, Geographic Information – Data quality measures
[ISO 19139] ISO/TS 19139:2007, Geographic information – Metadata – XML schema implementation
[ISO 19157] ISO/DIS 19157, Geographic information – Data quality
[OGC 06-103r4] Implementation Specification for Geographic Information - Simple feature access – Part 1: Common Architecture v1.2.1
NOTE This is an updated version of "EN ISO 19125-1:2004, Geographic information – Simple feature access – Part 1: Common architecture".
[Regulation 1205/2008/EC] Regulation 1205/2008/EC implementing Directive 2007/2/EC of the European Parliament and of the Council as regards metadata
[Regulation 976/2009/EC] Commission Regulation (EC) No 976/2009 of 19 October 2009 implementing Directive 2007/2/EC of the European Parliament and of the Council as regards the Network Services
[Regulation 1089/2010/EC] Commission Regulation (EU) No 1089/2010 of 23 November 2010 implementing Directive 2007/2/EC of the European Parliament and of the Council as regards interoperability of spatial data sets and services
2.4. Terms and definitions
General terms and definitions helpful for understanding the INSPIRE data specification documents are defined in the INSPIRE Glossary[13].
Specifically, for the theme Natural Risk Zones, the following terms are defined:
(1) Risk
Risk is the combination of the consequences of an event (hazard) and the associated likelihood/probability of its occurrence (ISO 31010).
EXAMPLE: 10000 People will lose their potable water supply due to earthquakes of magnitude 6 or above with a percentage likelihood.
(2) Hazard
A dangerous phenomenon, substance, human activity or condition that may cause loss of life, injury or other health impacts, property damage, loss of livelihoods and services, social and economic disruption, or environmental damage (UNISDR 2009).
EXAMPLE: Earthquake hazard.
(3) Exposure
People, property, systems, or other elements present in hazard zones that are thereby subject to potential losses (UNISDR 2009).
EXAMPLE: A hospital is in the affected area
(4) Vulnerability
The characteristics and circumstances of a community, system or asset that make it susceptible to the damaging effects of a hazard (UNISDR 2009).
EXAMPLE: Elderly residents
2.5. Symbols and abbreviations
ATS |
Abstract Test Suite |
CRED |
Centre of Research on the Epidemiology of Disasters) |
EC |
European Commission |
EEA |
European Environmental Agency |
EFFIS |
European Forest Fire Information System |
ETRS89 |
European Terrestrial Reference System 1989 |
ETRS89-LAEA |
Lambert Azimuthal Equal Area |
EVRS |
European Vertical Reference System |
FD |
EU Floods Directive (2007/60/EC) |
FWI |
Fire Weather Index |
GCM |
General Conceptual Model |
GML |
Geography Markup Language |
IAEG |
International Association for Engineering Geology |
IR |
Implementing Rule |
ISDSS |
Interoperability of Spatial Data Sets and Services |
ISO |
International Organization for Standardization |
ITRS |
International Terrestrial Reference System |
LAT |
Lowest Astronomical Tide |
LMO |
Legally Mandated Organisation |
Munich Re |
Münchener Rückversicherungs-Gesellschaft |
SDIC |
Spatial Data Interest Community |
SLD |
Styled Layer Descriptor |
TG |
Technical Guidance |
ULSE |
Universal Soil Loss Equation |
UML |
Unified Modeling Language |
UNISDR |
The United Nations Office for Disaster Reduction |
UTC |
Coordinated Universal Time |
XML |
EXtensible Markup Language |
2.6. How the Technical Guidelines map to the Implementing Rules
The schematic diagram in Figure 3 gives an overview of the relationships between the INSPIRE legal acts (the INSPIRE Directive and Implementing Rules) and the INSPIRE Technical Guidelines. The INSPIRE Directive and Implementing Rules include legally binding requirements that describe, usually on an abstract level, what Member States must implement.
In contrast, the Technical Guidelines define how Member States might implement the requirements included in the INSPIRE Implementing Rules. As such, they may include non-binding technical requirements that must be satisfied if a Member State data provider chooses to conform to the Technical Guidelines. Implementing these Technical Guidelines will maximise the interoperability of INSPIRE spatial data sets.
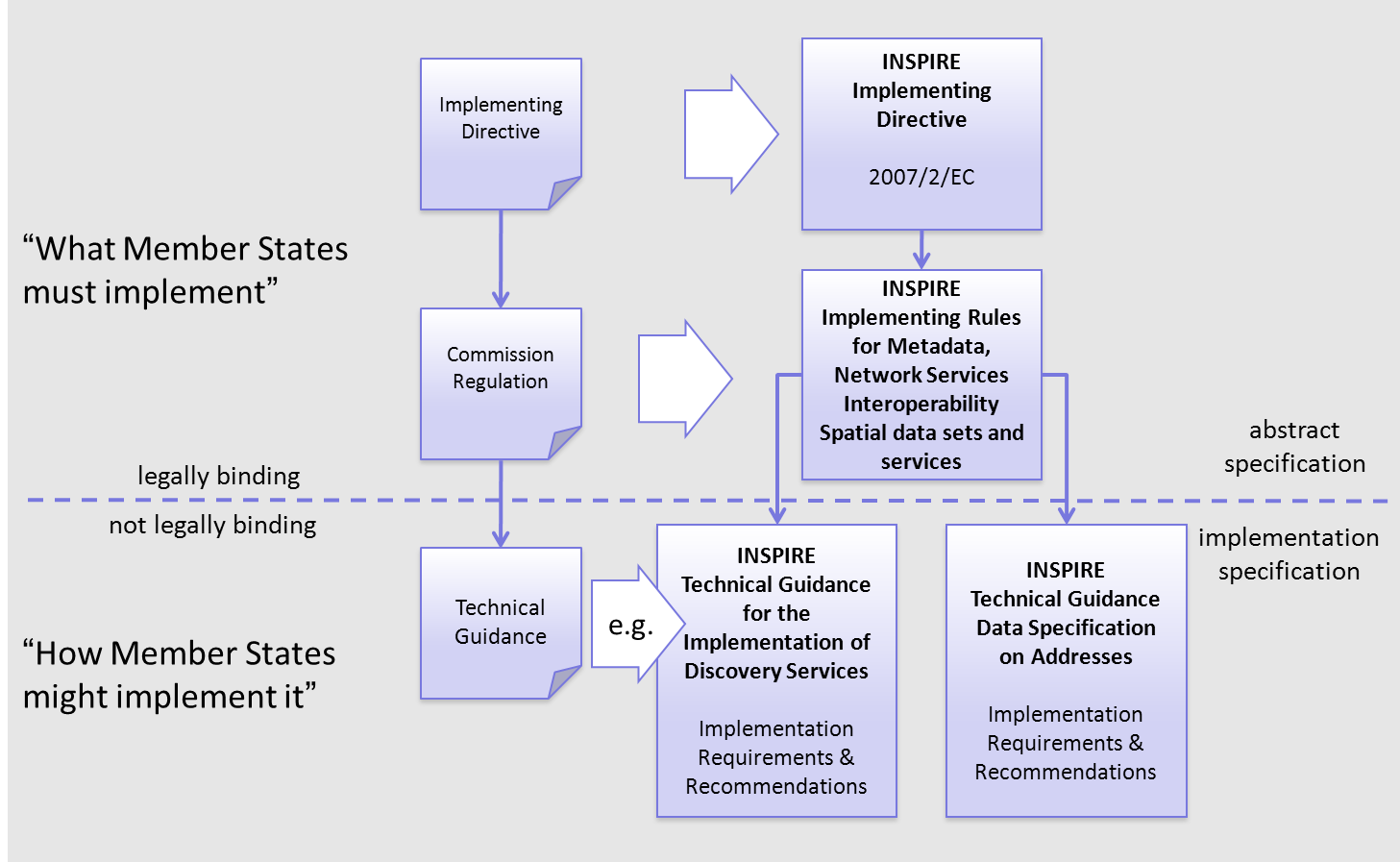
Figure 3 - Relationship between INSPIRE Implementing Rules and Technical Guidelines
2.6.1. Requirements
The purpose of these Technical Guidelines (Data specifications on Natural Risk Zones) is to provide practical guidance for implementation that is guided by, and satisfies, the (legally binding) requirements included for the spatial data theme Natural Risk Zones in the Regulation (Implementing Rules) on interoperability of spatial data sets and services. These requirements are highlighted in this document as follows:
|
📕
|
IR Requirement This style is used for requirements contained in the Implementing Rules on interoperability of spatial data sets and services (Commission Regulation (EU) No 1089/2010). |
For each of these IR requirements, these Technical Guidelines contain additional explanations and examples.
NOTE The Abstract Test Suite (ATS) in Annex A contains conformance tests that directly check conformance with these IR requirements.
Furthermore, these Technical Guidelines may propose a specific technical implementation for satisfying an IR requirement. In such cases, these Technical Guidelines may contain additional technical requirements that need to be met in order to be conformant with the corresponding IR requirement when using this proposed implementation. These technical requirements are highlighted as follows:
|
📒
|
TG Requirement X This style is used for requirements for a specific technical solution proposed in these Technical Guidelines for an IR requirement. |
NOTE 1 Conformance of a data set with the TG requirement(s) included in the ATS implies conformance with the corresponding IR requirement(s).
NOTE 2 In addition to the requirements included in the Implementing Rules on interoperability of spatial data sets and services, the INSPIRE Directive includes further legally binding obligations that put additional requirements on data providers. For example, Art. 10(2) requires that Member States shall, where appropriate, decide by mutual consent on the depiction and position of geographical features whose location spans the frontier between two or more Member States. General guidance for how to meet these obligations is provided in the INSPIRE framework documents.
2.6.2. Recommendations
In addition to IR and TG requirements, these Technical Guidelines may also include a number of recommendations for facilitating implementation or for further and coherent development of an interoperable infrastructure.
|
📘
|
Recommendation X Recommendations are shown using this style. |
NOTE The implementation of recommendations is not mandatory. Compliance with these Technical Guidelines or the legal obligation does not depend on the fulfilment of the recommendations.
2.6.3. Conformance
Annex A includes the abstract test suite for checking conformance with the requirements included in these Technical Guidelines and the corresponding parts of the Implementing Rules (Commission Regulation (EU) No 1089/2010).
3. Specification scopes
This data specification does not distinguish different specification scopes, but just considers one general scope.
NOTE For more information on specification scopes, see [ISO 19131:2007], clause 8 and Annex D.
4. Identification information
These Technical Guidelines are identified by the following URI:
NOTE ISO 19131 suggests further identification information to be included in this section, e.g. the title, abstract or spatial representation type. The proposed items are already described in the document metadata, executive summary, overview description (section 2) and descriptions of the application schemas (section 5). In order to avoid redundancy, they are not repeated here.
5. Data content and structure
5.1. Application schemas – Overview
5.1.1. Application schemas included in the IRs
Articles 3, 4 and 5 of the Implementing Rules lay down the requirements for the content and structure of the data sets related to the INSPIRE Annex themes.
|
📕
|
IR Requirement
|
The types to be used for the exchange and classification of spatial objects from data sets related to the spatial data theme Natural Risk Zones are defined in the following application schema: (see section 5.3)
-
NaturalRiskZones application schema describes the core normative concepts that build up the INSPIRE Natural Risk Zones data theme
The application schemas specify requirements on the properties of each spatial object including its multiplicity, domain of valid values, constraints, etc.
NOTE The application schemas presented in this section contain some additional information that is not included in the Implementing Rules, in particular multiplicities of attributes and association roles.
|
📒
|
TG Requirement 1 Spatial object types and data types shall comply with the multiplicities defined for the attributes and association roles in this section. |
An application schema may include references (e.g. in attributes or inheritance relationships) to common types or types defined in other spatial data themes. These types can be found in a sub-section called "Imported Types" at the end of each application schema section. The common types referred to from application schemas included in the IRs are addressed in Article 3.
|
📕
|
IR Requirement Types that are common to several of the themes listed in Annexes I, II and III to Directive 2007/2/EC shall conform to the definitions and constraints and include the attributes and association roles set out in Annex I. |
NOTE Since the IRs contain the types for all INSPIRE spatial data themes in one document, Article 3 does not explicitly refer to types defined in other spatial data themes, but only to types defined in external data models.
Common types are described in detail in the Generic Conceptual Model [DS-D2.7], in the relevant international standards (e.g. of the ISO 19100 series) or in the documents on the common INSPIRE models [DS-D2.10.x]. For detailed descriptions of types defined in other spatial data themes, see the corresponding Data Specification TG document [DS-D2.8.x].
5.1.2. Additional recommended application schemas
-
In addition to the application schemas listed above, the following additional application schema has been defined for the theme Natural Risk Zones (see Annex D):
The Floods_Example_Model application schema represents the extension of the core NZ application schema (NaturalRiskZones) as one possible example of how Floods Directive requirements could be addressed.
These additional application schemas are not included in the IRs. They typically address requirements from specific (groups of) use cases and/or may be used to provide additional information. They are included in this specification in order to improve interoperability also for these additional aspects and to illustrate the extensibility of the application schemas included in the IRs.
|
📘
|
Recomendation 1 Additional and/or use case-specific information related to the theme Natural Risk Zones should be made available using the spatial object types and data types specified in the following application schema(s): Floods_Example_Model |
5.2. Basic notions
This section explains some of the basic notions used in the INSPIRE application schemas. These explanations are based on the GCM [DS-D2.5].
5.2.1. Notation
5.2.1.1. Unified Modeling Language (UML)
The application schemas included in this section are specified in UML, version 2.1. The spatial object types, their properties and associated types are shown in UML class diagrams.
NOTE For an overview of the UML notation, see Annex D in [ISO 19103].
The use of a common conceptual schema language (i.e. UML) allows for an automated processing of application schemas and the encoding, querying and updating of data based on the application schema – across different themes and different levels of detail.
The following important rules related to class inheritance and abstract classes are included in the IRs.
|
📕
|
IR Requirement (…)
|
The use of UML conforms to ISO 19109 8.3 and ISO/TS 19103 with the exception that UML 2.1 instead of ISO/IEC 19501 is being used. The use of UML also conforms to ISO 19136 E.2.1.1.1-E.2.1.1.4.
NOTE ISO/TS 19103 and ISO 19109 specify a profile of UML to be used in conjunction with the ISO 19100 series. This includes in particular a list of stereotypes and basic types to be used in application schemas. ISO 19136 specifies a more restricted UML profile that allows for a direct encoding in XML Schema for data transfer purposes.
To model constraints on the spatial object types and their properties, in particular to express data/data set consistency rules, OCL (Object Constraint Language) is used as described in ISO/TS 19103, whenever possible. In addition, all constraints are described in the feature catalogue in English, too.
NOTE Since "void" is not a concept supported by OCL, OCL constraints cannot include expressions to test whether a value is a void value. Such constraints may only be expressed in natural language.
5.2.1.2. Stereotypes
In the application schemas in this section several stereotypes are used that have been defined as part of a UML profile for use in INSPIRE [DS-D2.5]. These are explained in Table 1 below.
Table 1 – Stereotypes (adapted from [DS-D2.5])
Stereotype |
Model element |
Description |
applicationSchema |
Package |
An INSPIRE application schema according to ISO 19109 and the Generic Conceptual Model. |
leaf |
Package |
A package that is not an application schema and contains no packages. |
featureType |
Class |
A spatial object type. |
type |
Class |
A type that is not directly instantiable, but is used as an abstract collection of operation, attribute and relation signatures. This stereotype should usually not be used in INSPIRE application schemas as these are on a different conceptual level than classifiers with this stereotype. |
dataType |
Class |
A structured data type without identity. |
union |
Class |
A structured data type without identity where exactly one of the properties of the type is present in any instance. |
codeList |
Class |
A code list. |
import |
Dependency |
The model elements of the supplier package are imported. |
voidable |
Attribute, association role |
A voidable attribute or association role (see section 5.2.2). |
lifeCycleInfo |
Attribute, association role |
If in an application schema a property is considered to be part of the life-cycle information of a spatial object type, the property shall receive this stereotype. |
version |
Association role |
If in an application schema an association role ends at a spatial object type, this stereotype denotes that the value of the property is meant to be a specific version of the spatial object, not the spatial object in general. |
5.2.2. Voidable characteristics
The «voidable» stereotype is used to characterise those properties of a spatial object that may not be present in some spatial data sets, even though they may be present or applicable in the real world. This does not mean that it is optional to provide a value for those properties.
For all properties defined for a spatial object, a value has to be provided – either the corresponding value (if available in the data set maintained by the data provider) or the value of void. A void value shall imply that no corresponding value is contained in the source spatial data set maintained by the data provider or no corresponding value can be derived from existing values at reasonable costs.
|
📘
|
Recomendation 2 The reason for a void value should be provided where possible using a listed value from the VoidReasonValue code list to indicate the reason for the missing value. |
The VoidReasonValue type is a code list, which includes the following pre-defined values:
-
Unpopulated: The property is not part of the dataset maintained by the data provider. However, the characteristic may exist in the real world. For example when the "elevation of the water body above the sea level" has not been included in a dataset containing lake spatial objects, then the reason for a void value of this property would be 'Unpopulated'. The property receives this value for all spatial objects in the spatial data set.
-
Unknown: The correct value for the specific spatial object is not known to, and not computable by the data provider. However, a correct value may exist. For example when the "elevation of the water body above the sea level" of a certain lake has not been measured, then the reason for a void value of this property would be 'Unknown'. This value is applied only to those spatial objects where the property in question is not known.
-
Withheld: The characteristic may exist, but is confidential and not divulged by the data provider.
NOTE It is possible that additional reasons will be identified in the future, in particular to support reasons / special values in coverage ranges.
The «voidable» stereotype does not give any information on whether or not a characteristic exists in the real world. This is expressed using the multiplicity:
-
If a characteristic may or may not exist in the real world, its minimum cardinality shall be defined as 0. For example, if an Address may or may not have a house number, the multiplicity of the corresponding property shall be 0..1.
-
If at least one value for a certain characteristic exists in the real world, the minimum cardinality shall be defined as 1. For example, if an Administrative Unit always has at least one name, the multiplicity of the corresponding property shall be 1..*.
In both cases, the «voidable» stereotype can be applied. In cases where the minimum multiplicity is 0, the absence of a value indicates that it is known that no value exists, whereas a value of void indicates that it is not known whether a value exists or not.
EXAMPLE If an address does not have a house number, the corresponding Address object should not have any value for the «voidable» attribute house number. If the house number is simply not known or not populated in the data set, the Address object should receive a value of void (with the corresponding void reason) for the house number attribute.
5.2.3. Code lists
Code lists are modelled as classes in the application schemas. Their values, however, are managed outside of the application schema.
5.2.3.1. Code list types
The IRs distinguish the following types of code lists.
|
📕
|
IR Requirement
|
The type of code list is represented in the UML model through the tagged value extensibility, which can take the following values:
-
none, representing code lists whose allowed values comprise only the values specified in the IRs (type a);
-
narrower, representing code lists whose allowed values comprise the values specified in the IRs and narrower values defined by data providers (type b);
-
open, representing code lists whose allowed values comprise the values specified in the IRs and additional values at any level defined by data providers (type c); and
-
any, representing code lists, for which the IRs do not specify any allowed values, i.e. whose allowed values comprise any values defined by data providers (type d).
|
📘
|
Recomendation 3 Additional values defined by data providers should not replace or redefine any value already specified in the IRs. |
NOTE This data specification may specify recommended values for some of the code lists of type (b), (c) and (d) (see section 5.2.4.3). These recommended values are specified in a dedicated Annex.
In addition, code lists can be hierarchical, as explained in Article 6(5) of the IRs.
|
📕
|
IR Requirement (…)
|
The type of code list and whether it is hierarchical or not is also indicated in the feature catalogues.
5.2.3.2. Obligations on data providers
|
📕
|
IR Requirement (….)
|
Article 6(6) obliges data providers to use only values that are allowed according to the specification of the code list. The "allowed values according to the specification of the code list" are the values explicitly defined in the IRs plus (in the case of code lists of type (b), (c) and (d)) additional values defined by data providers.
For attributes whose type is a code list of type (b), (c) or (d) data providers may use additional values that are not defined in the IRs. Article 6(6) requires that such additional values and their definition be made available in a register. This enables users of the data to look up the meaning of the additional values used in a data set, and also facilitates the re-use of additional values by other data providers (potentially across Member States).
NOTE Guidelines for setting up registers for additional values and how to register additional values in these registers is still an open discussion point between Member States and the Commission.
5.2.3.3. Recommended code list values
For code lists of type (b), (c) and (d), this data specification may propose additional values as a recommendation (in a dedicated Annex). These values will be included in the INSPIRE code list register. This will facilitate and encourage the usage of the recommended values by data providers since the obligation to make additional values defined by data providers available in a register (see section 5.2.4.2) is already met.
|
📘
|
Recomendation 4 Where these Technical Guidelines recommend values for a code list in addition to those specified in the IRs, these values should be used. |
NOTE For some code lists of type (d), no values may be specified in these Technical Guidelines. In these cases, any additional value defined by data providers may be used.
5.2.3.4. Governance
The following two types of code lists are distinguished in INSPIRE:
-
Code lists that are governed by INSPIRE (INSPIRE-governed code lists). These code lists will be managed centrally in the INSPIRE code list register. Change requests to these code lists (e.g. to add, deprecate or supersede values) are processed and decided upon using the INSPIRE code list register’s maintenance workflows.
INSPIRE-governed code lists will be made available in the INSPIRE code list register at http://inspire.ec.europa.eu/codelist/<CodeListName>. They will be available in SKOS/RDF, XML and HTML. The maintenance will follow the procedures defined in ISO 19135. This means that the only allowed changes to a code list are the addition, deprecation or supersession of values, i.e. no value will ever be deleted, but only receive different statuses (valid, deprecated, superseded). Identifiers for values of INSPIRE-governed code lists are constructed using the pattern http://inspire.ec.europa.eu/codelist/<CodeListName>/<value>.
-
Code lists that are governed by an organisation outside of INSPIRE (externally governed code lists). These code lists are managed by an organisation outside of INSPIRE, e.g. the World Meteorological Organization (WMO) or the World Health Organization (WHO). Change requests to these code lists follow the maintenance workflows defined by the maintaining organisations. Note that in some cases, no such workflows may be formally defined.
Since the updates of externally governed code lists is outside the control of INSPIRE, the IRs and these Technical Guidelines reference a specific version for such code lists.
The tables describing externally governed code lists in this section contain the following columns:
-
The Governance column describes the external organisation that is responsible for maintaining the code list.
-
The Source column specifies a citation for the authoritative source for the values of the code list. For code lists, whose values are mandated in the IRs, this citation should include the version of the code list used in INSPIRE. The version can be specified using a version number or the publication date. For code list values recommended in these Technical Guidelines, the citation may refer to the "latest available version".
-
In some cases, for INSPIRE only a subset of an externally governed code list is relevant. The subset is specified using the Subset column.
-
The Availability column specifies from where (e.g. URL) the values of the externally governed code list are available, and in which formats. Formats can include machine-readable (e.g. SKOS/RDF, XML) or human-readable (e.g. HTML, PDF) ones.
Code list values are encoded using http URIs and labels. Rules for generating these URIs and labels are specified in a separate table.
-
|
📘
|
Recomendation 5 The http URIs and labels used for encoding code list values should be taken from the INSPIRE code list registry for INSPIRE-governed code lists and generated according to the relevant rules specified for externally governed code lists. |
NOTE Where practicable, the INSPIRE code list register could also provide http URIs and labels for externally governed code lists.
5.2.3.5. Vocabulary
For each code list, a tagged value called "vocabulary" is specified to define a URI identifying the values of the code list. For INSPIRE-governed code lists and externally governed code lists that do not have a persistent identifier, the URI is constructed following the pattern http://inspire.ec.europa.eu/codelist/<UpperCamelCaseName>;.
If the value is missing or empty, this indicates an empty code list. If no sub-classes are defined for this empty code list, this means that any code list may be used that meets the given definition.
An empty code list may also be used as a super-class for a number of specific code lists whose values may be used to specify the attribute value. If the sub-classes specified in the model represent all valid extensions to the empty code list, the subtyping relationship is qualified with the standard UML constraint "\{complete,disjoint}".
5.2.4. Identifier management
|
📕
|
IR Requirement
|
NOTE 1 An external object identifier is a unique object identifier which is published by the responsible body, which may be used by external applications to reference the spatial object. [DS-D2.5]
NOTE 2 Article 9(1) is implemented in each application schema by including the attribute inspireId of type Identifier.
NOTE 3 Article 9(2) is ensured if the namespace and localId attributes of the Identifier remains the same for different versions of a spatial object; the version attribute can of course change.
5.2.5. Geometry representation
|
📕
|
IR Requirement
|
NOTE 1 The specification restricts the spatial schema to 0-, 1-, 2-, and 2.5-dimensional geometries where all curve interpolations are linear and surface interpolations are performed by triangles.
NOTE 2 The topological relations of two spatial objects based on their specific geometry and topology properties can in principle be investigated by invoking the operations of the types defined in ISO 19107 (or the methods specified in EN ISO 19125-1).
5.2.6. Temporality representation
The application schema(s) use(s) the derived attributes "beginLifespanVersion" and "endLifespanVersion" to record the lifespan of a spatial object.
The attributes "beginLifespanVersion" specifies the date and time at which this version of the spatial object was inserted or changed in the spatial data set. The attribute "endLifespanVersion" specifies the date and time at which this version of the spatial object was superseded or retired in the spatial data set.
NOTE 1 The attributes specify the beginning of the lifespan of the version in the spatial data set itself, which is different from the temporal characteristics of the real-world phenomenon described by the spatial object. This lifespan information, if available, supports mainly two requirements: First, knowledge about the spatial data set content at a specific time; second, knowledge about changes to a data set in a specific time frame. The lifespan information should be as detailed as in the data set (i.e., if the lifespan information in the data set includes seconds, the seconds should be represented in data published in INSPIRE) and include time zone information.
NOTE 2 Changes to the attribute "endLifespanVersion" does not trigger a change in the attribute "beginLifespanVersion".
|
📕
|
IR Requirement (…)
|
NOTE The requirement expressed in the IR Requirement above will be included as constraints in the UML data models of all themes.
|
📘
|
Recomendation 6 If life-cycle information is not maintained as part of the spatial data set, all spatial objects belonging to this data set should provide a void value with a reason of "unpopulated". |
5.2.6.1. Validity of the real-world phenomena
The application schema(s) use(s) the attributes "validFrom" and "validTo" to record the validity of the real-world phenomenon represented by a spatial object.
The attributes "validFrom" specifies the date and time at which the real-world phenomenon became valid in the real world. The attribute "validTo" specifies the date and time at which the real-world phenomenon is no longer valid in the real world.
Specific application schemas may give examples what "being valid" means for a specific real-world phenomenon represented by a spatial object.
|
📕
|
IR Requirement (…)
|
NOTE The requirement expressed in the IR Requirement above will be included as constraints in the UML data models of all themes.
5.2.7. Coverages
Coverage functions are used to describe characteristics of real-world phenomena that vary over space and/or time. Typical examples are temperature, elevation, precipitation, imagery. A coverage contains a set of such values, each associated with one of the elements in a spatial, temporal or spatio-temporal domain. Typical spatial domains are point sets (e.g. sensor locations), curve sets (e.g. isolines), grids (e.g. orthoimages, elevation models), etc.
In INSPIRE application schemas, coverage functions are defined as properties of spatial object types where the type of the property value is a realisation of one of the types specified in ISO 19123.
To improve alignment with coverage standards on the implementation level (e.g. ISO 19136 and the OGC Web Coverage Service) and to improve the cross-theme harmonisation on the use of coverages in INSPIRE, an application schema for coverage types is included in the Generic Conceptual Model in 9.9.4. This application schema contains the following coverage types:
-
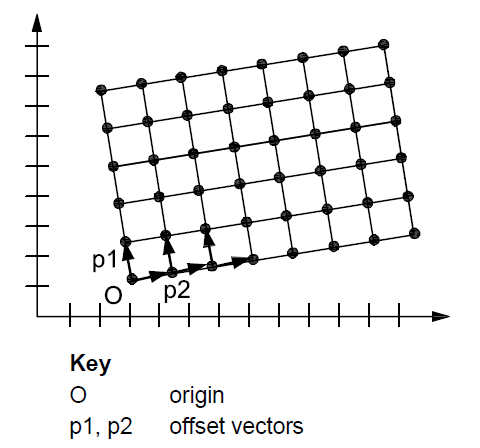
RectifiedGridCoverage: coverage whose domain consists of a rectified grid – a grid for which there is an affine transformation between the grid coordinates and the coordinates of a coordinate reference system (see Figure 4, left).
-
ReferenceableGridCoverage: coverage whose domain consists of a referenceable grid – a grid associated with a transformation that can be used to convert grid coordinate values to values of coordinates referenced to a coordinate reference system (see Figure 4, right).
In addition, some themes make reference to the types TimeValuePair and Timeseries defined in Taylor, Peter (ed.), OGC® WaterML 2.0: Part 1 – Timeseries, v2.0.0, Open Geospatial Consortium, 2012. These provide a representation of the time instant/value pairs, i.e. time series (see Figure 5).
Where possible, only these coverage types (or a subtype thereof) are used in INSPIRE application schemas.
|
|
(Source: ISO 19136:2007) |
(Source: GML 3.3.0) |
Figure 4 – Examples of a rectified grid (left) and a referenceable grid (right)
Figure 5 – Example of a time series
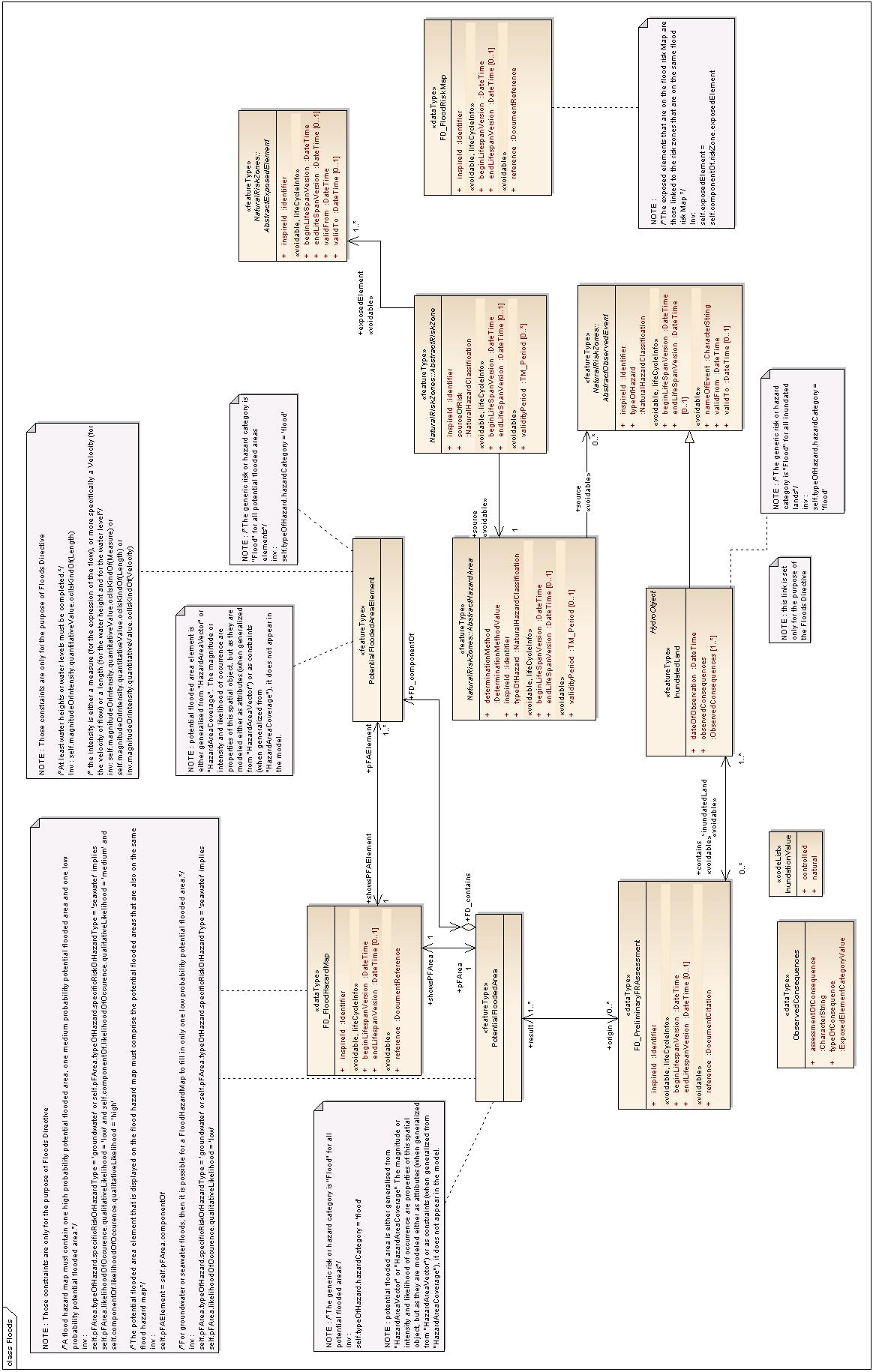
5.3. Application schema NaturalRiskZones
5.3.1. Description
5.3.1.1. Narrative description
The application schema covers elements that are seen as necessary to describe INSPIRE Natural Risk Zones. This common model schema allows users to model the main concepts as defined in Chapter 2 (hazard, vulnerability, exposure, risk and observed event).
We present in these data specifications a model in which the concepts are abstract and can be specialized both in vectors (and therefore based upon EN-ISO 19107 standard) and in coverages (and therefore based upon EN-ISO 19123 Standard).
This is done in order to create a framework which enables exchanges of data that are either vectors or coverages, considering that any of the 4 spatial objects can be modelled in one of those 2 ways.
There are 4 kinds of spatial objects that are modelled both as vectors and as coverages:
-
Hazard area
-
Exposed element
-
Risk zone
-
Observed event
For each of them, 3 spatial object types are created:
-
An abstract spatial object type that contains the properties (attributes, or constraints) of the spatial object that are common both to its vector representation and to its coverage representation. These abstract spatial object types have their names prefixed by "Abstract".
-
A vector spatial object type that is generated from the abstract spatial object. It has the properties that are specific to the vector representation, such as the definition of the geometry.
-
A coverage spatial object type that is generated both from the abstract spatial object and a generic coverage spatial object type (detailed later in the chapter). It has the properties that are specific to coverage representation, such as the definition of the domain and the definition of the range. These coverage spatial object types have their names suffixed by "Coverage".
NOTE If a data provider has data in a vector form, then he will make use of the vector spatial object types. If a data provider has data in a coverage form, then he will make use of the coverage spatial object types.
5.3.1.2. UML Overview
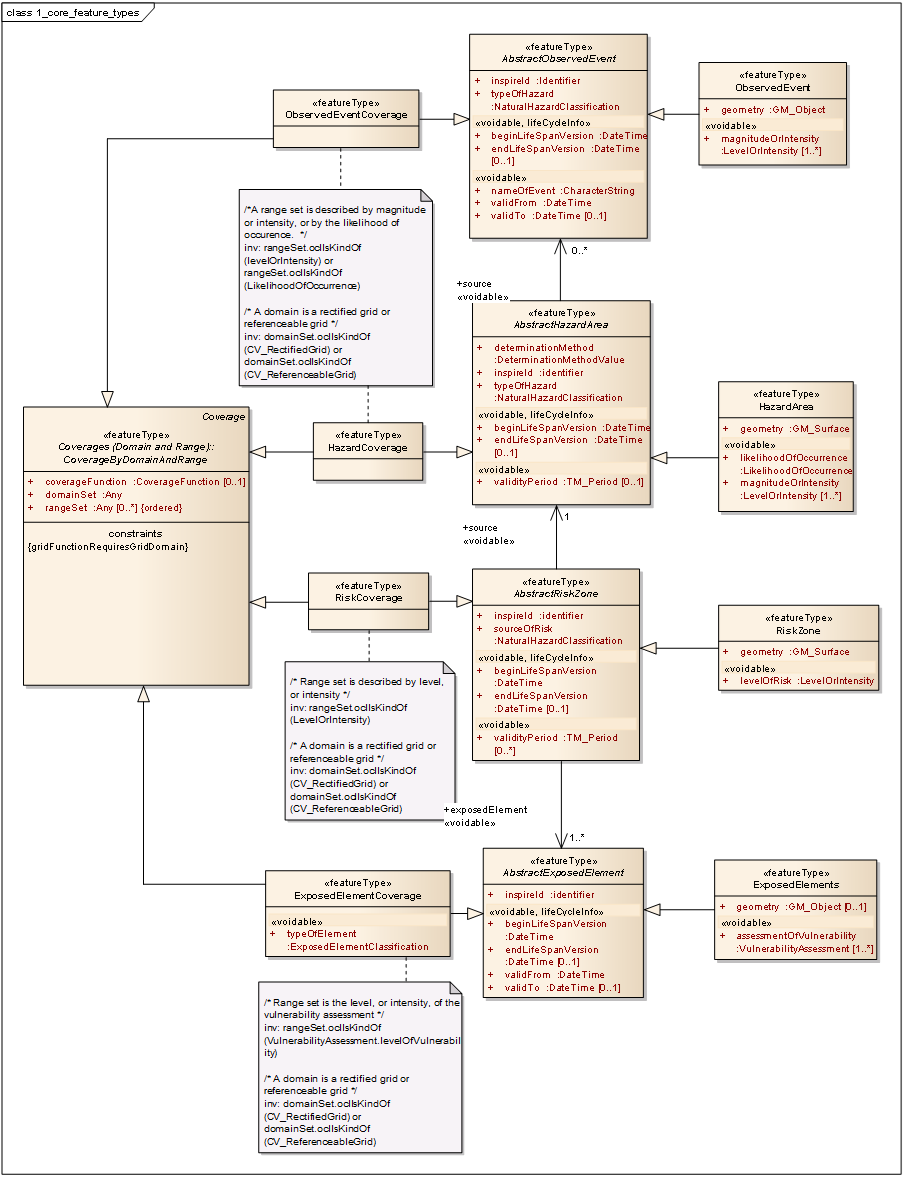
Figure 6 – UML class diagram: Overview of the NaturalRiskZones application schema
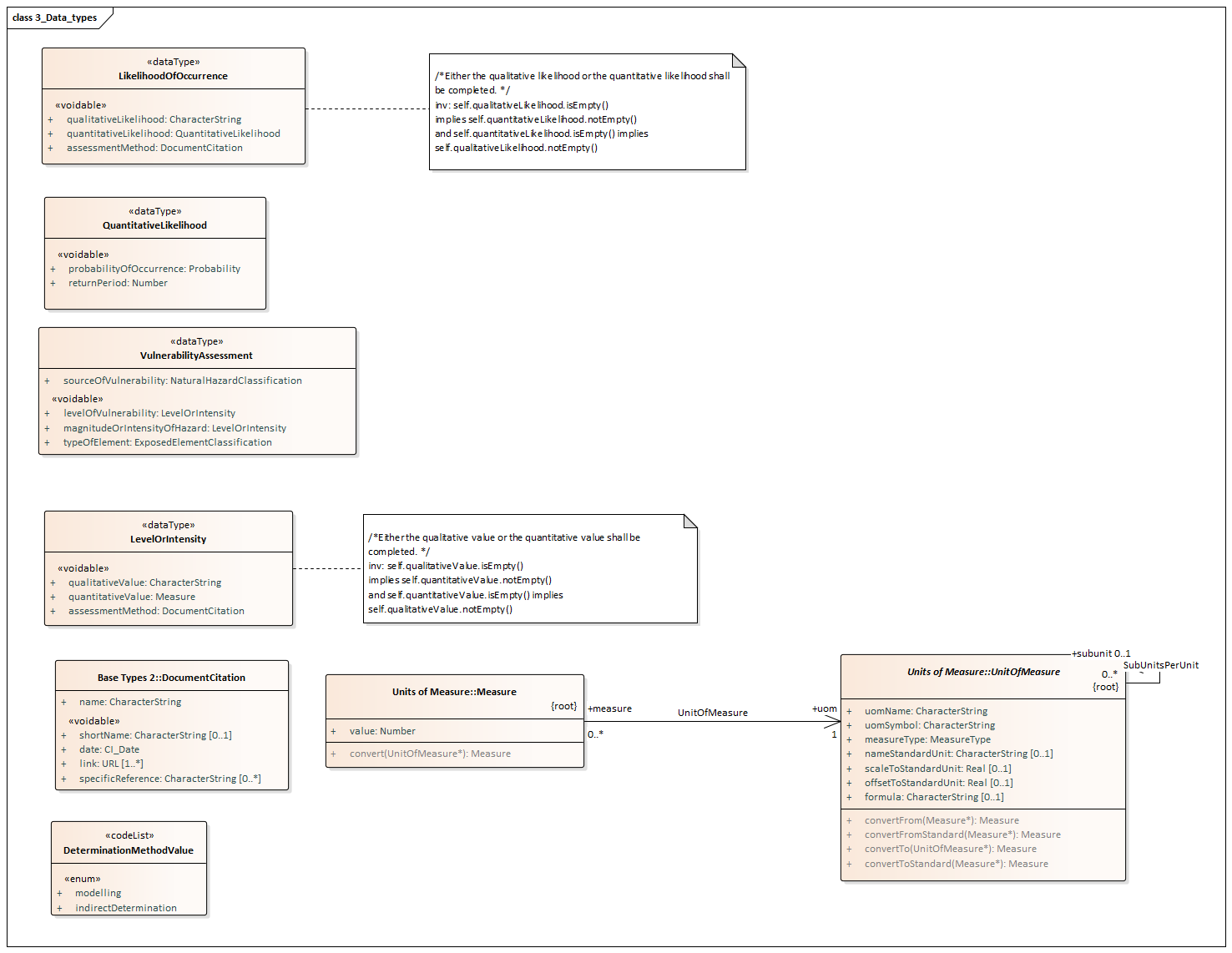
Figure 7: UML class diagram: Overview of the NaturalRiskZones data types
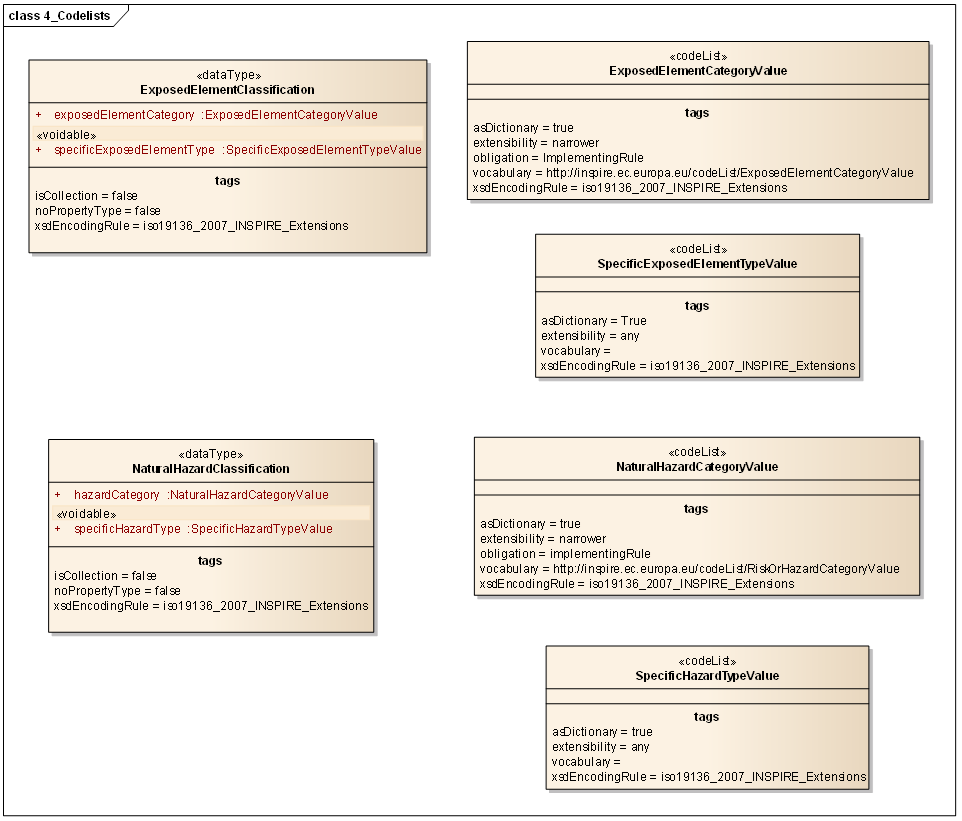
Figure 8: UML class diagram: Overview of the NaturalRiskZones code lists
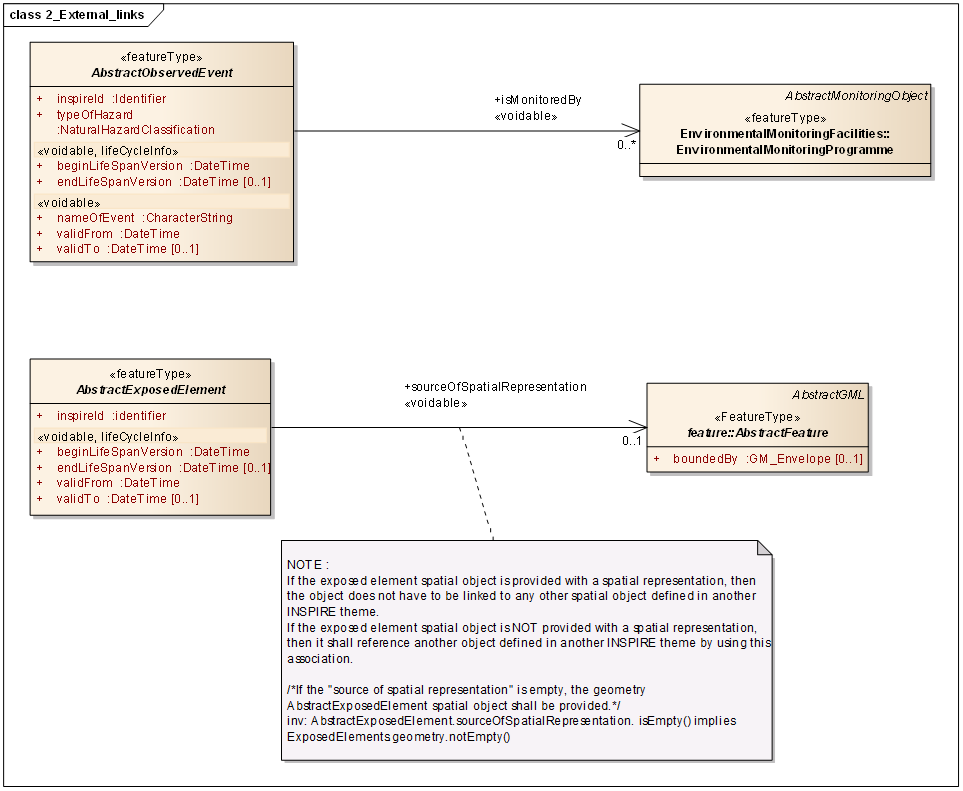
Figure 9: UML class diagram: Overview of the External links
Detailed description of major types:
HAZARD AREAS
Hereunder are detailed the following spatial object types:
-
"AbstractHazardArea"
-
"HazardAreaVector"
-
"HazardCoverage"
The following data types are also detailed:
-
"DeterminationMethod"
-
"NaturalHazardClassification"
-
"LikelihoodOfOccurrence"
-
"LevelOrIntensity"
Common properties of "AbstractHazardArea"
The objects of the "HazardArea" spatial object type have following properties:
-
An identifier
-
A method of determination: There are several ways to delineate the perimeter of a hazard: to compute it according to a model, or to define it by interpretation of available data and/or information. This is modelled using the "DeterminationMethod" data type. This data type, (code list) has 2 possible values :
-
"modelling"
-
"indirect determination"
-
-
A type of hazard: this property is modelled with a "NaturalHazardClassification" data type
Natural hazards classifications from the scientific literature focus in the nature of the processes or in the origin of the process itself, the physics, chemistry or biology involved (or all together) in causing damage with little regard (if any) for damage itself. They deal with finite systems or finite processes with finite variables and finite expectable results.
Due to the fact that in natural hazard community there is not a widely accepted and used classification of types of natural hazards, the TWG NZ team, in order to facilitate interoperability of hazard data, has defined a list of generic types of hazards.
A data type "NaturalHazardClassification" containts:
-
An attribute that refers to the code list: "NaturalHazardCategoryValue".
This hierarchical code list has been elaborated to facilitate high level interoperability. It is already populated with a dozen of natural hazard types (see Annex C). However this code list can be extended by hazard data providers with narrower terms.
-
An attribute that refers to the empty code list: "SpecificHazardTypeValue". This code is a placeholder to enable a hazard data provider to enter a specific denomination of a hazard type.
-
-
The date the object was entered in the dataset, and the date the object was removed or superseded from the dataset. Those attributes are "beginLifeSpanVersion" and "endLifeSpanVersion"
-
The period of validity ("validityPeriod"):
The period of validity is the future finite time frame where the hazard applies. The same hazard assessment can be valid for a specific period, or even for several specific periods: the hazard assessment of forest fires may actually be valid only in summer, or maybe in summer or in winter (but not all year long). This attribute can also be used for multi-temporal hazard analysis.
-
An association link to the "Observed events"
It is possible to use the location of an observed event as an input for the hazard area modeling. A hazard area may therefore have an observed event as a "source". An association link between the "hazard area" spatial object type and the "observed event" spatial object type is set to express this. A hazard area may have 0 (if no observed event was used during the process of hazard area modelling) or 1 observed event. This association link can only be navigated from the hazard area to the observed event.
Specific properties of "HazardArea"
The discrete representation of a hazard area has also the geometry as mandatory, which is modeled as a "GM_Surface". All hazard areas are therefore modeled as polygons.
It has also the following two attributes:
-
The likelihood of occurrence
The likelihood of occurrence is a general concept relating to the chance of an event occurring. This is modeled by the "LikelihoodOfOccurrence" data type.
It is assumed that a likelihood of occurrence can be expressed either qualitatively, or quantitatively. Moreover, a value without any further explanation is of very little interest.
The data type "Likelihood of occurrence" is a set of 3 attributes:
-
An "assessmentMethod", which refers to the method used to express the likelihood of a hazard event
-
A "qualitativeLikelihood", which enables to describe in narrative form the assessment of the likelihood of occurrence of a hazard.event.
-
A "quantitativeLikelihood, which is either a probability of occurrence, or a return period.
A return period is a long-term average interval of time or number of years within which an event will be equaled or exceeded. The probability of occurrence is the inverse value of the return period. Therefore 2 attributes are modeled: a "returnPeriod" attribute and a "probabilityOfOccurrence" attribute.
-
-
The magnitude, or intensity
A magnitude, or intensity, can be expressed either qualitatively, or quantitatively. Moreover, a value without any further explanation is of very little interest.
The data type "LevelOrIntensity" is a set of 3 attributes:
-
A qualitative value, which is a character string
-
A quantitative value, which is modeled as a measure (that is to say a number and a unit)
-
A reference to the method in which further information can be taken. This is modeled using the INSPIRE common data type "DocumentCitation".that is described in the INSPIRE Generic Conceptual Model.
-
-
Specific properties of "HazardAreaCoverage"
In the related coverage representation, the values that vary over space (and therefore declared as the range of the coverage) are either the magnitude or intensity of a hazard, or the likelihood of occurrence of a hazard.
EXPOSED ELEMENTS
Hereunder are detailed the following spatial object types:
-
"AbstractExposedElement"
-
"ExposedElement"
-
"ExposedElementCoverage"
The following types are also detailed:
-
"VulnerabilityAssessment"
-
"ExposedElementClassification",
-
"RiskOrHazardCategoryValue".
Common properties of "AbstractExposedElement"
The "ExposedElement" spatial object type refers to the spatial representation of people, property, systems, or other elements present in hazard zones that are thereby subject to potential losses. The assessment or calculation of vulnerability may be conducted over those spatial objects.
The "AbstractExposedElement" is linked to the "AbstractFeature" GML type.
NOTE Potentially, any kind of any object of the real world can be considered as being exposed to a natural hazard, and therefore could fit in this spatial object type. Some of them may also be provided under another INSPIRE spatial object type.
To properly model exposed elements two scenarios are taken into account:
-
The spatial representation of an exposed element is defined and provided by another INSPIRE theme. In this case, the exposed element object shall reference the object. The reference is made by instantiating the association link between "ExposedElement" and the abstract GML "AbstractFeature". This "AbstractFeature" encompasses any spatial object type of any INSPIRE data specifications. Object referencing is used to avoid any duplication of geometry between INSPIRE spatial objects.
-
An exposed element is not defined in another INSPIRE theme. In this case, the spatial representation of the object shall be provided using the INSPIRE NZ "ExposedElement" spatial object type, and the object does not have to be linked to any other spatial object defined in another INSPIRE theme.
The "ExposedElement" spatial object type has also following properties:
-
An identifier
-
The date the object was entered in the dataset, and the date the object was removed or superseded from the dataset. Those attributes are "beginLifeSpanVersion" and "endLifeSpanVersion"
-
The date the object started to exist in the real world, and the date from which the object no longer exist in the real world (if so). Those attributes are "validFrom" and "validTo".
Specific properties of the "ExposedElement"
The geometry of a discrete representation of an exposed element is modelled as "GM_Object", and basically allows any kind of geometric primitives. The multiplicity of this attribute is "0 or 1", due to the fact that an exposed element can reference another object defined in another INSPIRE data theme.
In addition to this, any spatial object of the "ExposedElementVector" spatial object type has the "assessmentOfVulnerability" as a voidable attribute.
The same exposed element may have one or several vulnerability assessments, as the assessment depends both on the type of natural hazard it is exposed to and on the level or intensity of the hazard.
Any "VulnerabilityAssessment" has following properties:
-
the "sourceOfVulnerability"
This refers to the type of hazard to which the vulnerability of the exposed element is assessed (or calculated) using the "NaturalHazardClassification".
-
The "levelOfVulnerability"
This is the result of the assessment of the vulnerability. This property is modeled as a "LevelOrIntensity" data type.
-
The magnitude, or intensity, of the hazard according to which the vulnerability of the exposed element is assessed (or calculated). This property is modeled as a "LevelOrIntensity" data type.
-
The "typeOfElement"
As there is currently not a widely used list or classification of types of exposed elements, a data type called "ExposedElementClassification" was defined to facilitate data interoperability.
It contains:
-
A mandatory attribute that refers to an existing code list: the "ExposedElementCategoryValue". This hierarchical code list has been elaborated to facilitate high level interoperability. It is already populated with generic types of exposed elements (see Annex C). However this code list can be extended by exposed data providers with narrower terms.
-
An attribute that refers to the empty code list: "SpecificExposedElementTypeValue". This code is a placeholder to enable exposed data providers to enter a specific denomination of a exposed element type.
-
Specific properties of "ExposedElementCoverage"
The exposed element coverage has the attribute, which is the "typeOfElement". This is modelled by the ""ExposedElementClassification" data type.
In the related coverage representation, the values that vary over space (and therefore declared as the range of the coverage) level or intensity of the vulnerability of assessment.
RISK ZONES
Hereunder are detailed the following spatial object types:
-
"AbstractRiskZone"
-
"RiskZone"
-
"RiskZoneCoverage"
Common properties of "AbstractRiskZone"
A risk zone is defined as the spatial extent of a combination of the consequences of an event (hazard) and the associated probability/likelihood of its occurrence.
It has following properties:
-
An identifier
-
A "sourceOfRisk"
The source of risk refers to the type of hazard that engenders the risk. In the model, the "sourceOfRisk" refers to the "NaturalHazardClassification" data type.
-
The date the object was entered in the dataset, and the date the object was removed or superseded from the dataset. Those attributes are "beginLifeSpanVersion" and "endLifeSpanVersion"
-
A period of validity ("validityPeriod"). – see Hazard Zones section above.
-
An association to the "HazardArea"
The delineation of a risk zone results from the co-occurrence over the same place of a natural hazard with elements that are vulnerable to this hazard type. As a consequence, a risk zone is potentially linked to a hazard area (and vice-versa as the creation of a hazard area spatial object may have preceded the creation of a risk zone object).
An association link between the "HazardArea" spatial object type and the "RiskZone" spatial object type is set to express this. Each risk zone should have 1 hazard area as a source.
This association link is voidable, and can only be navigated from the risk zone to the hazard area.
-
An association to the "ExposedEelement"
In the same way as there is a link between hazard area and risk zone, there is also a link between risk zone and exposed elements. A risk zone is potentially linked to exposed elements in so far as an exposed element should have been identified as such within the process of production of a risk zone.
An association link between the "ExposedElement" spatial object type and the "RiskZone" spatial object type is set to express this. There is at least one exposed element for each risk zone.
This association link is voidable, and can only be navigated from the risk zone to the exposed element.
Specific properties of "RiskZone"
The vector representation of a risk zone is modelled as a "GM_Surface". All risk zones are therefore modelled as polygons.
It has also the following attribute:
-
The "levelOfRisk".
It is an assessment of the combination of the consequences of an event (hazard) and the associated probability/likelihood of the occurrence of the event. This property is modelled as a "LevelOrIntensity" data type.
Specific properties of "RiskZoneCoverage"
In the related coverage representation, the values that vary over space (and therefore declared as the range of the coverage) is the level of risk. As the level of risk is modelled by the "LevelOrIntensity" data type, the constraint on the range set of the coverage addresses the "LevelOrIntensity" data type.
OBSERVED EVENTS
Hereunder are detailed the following spatial object types:
-
"AbstractObservedEvent"
-
"ObservedEvent"
-
"ObservedEventCoverage"
Common properties of "AbstractObservedEvent"
An observed event refers to the spatial representation of a natural phenomenon relevant to the study of natural hazards which occurred, or is currently occurring, and which have been observed.
The abstract observed event spatial object type has following properties:
-
An identifier
-
A "typeOfHazard": this property is modelled using the "NaturalHazardClassification" data type
-
The "nameOfEvent": an observed event can have a commonly known name (such as the "Xynthia" tempest that stroke part of the Atlantic coast-line of France in early 2010).
-
"ValidFrom": which provides piece of information about the date of appearance of the event ("February 26th 2010" for the "Xynthia" tempest)
-
"ValidTo" : which provides piece of information about the ending date of the event ("March 1st 2010" for the "Xynthia" tempest)
-
The date the object was entered in the dataset, and the date the object was removed or superseded from the dataset. Those attributes are "beginLifeSpanVersion" and "endLifeSpanVersion"
-
An association to the "EnvironmentalMonitoringProgram"
As it is a spatial object that may exist in the real world, an observed event can be monitored. To express this, an voidable association link is set between the "AbstractObservedEvent" spatial object type, and the "EnvironmentalMonitoringProgram" spatial object type designed by TWG EF. An observed event can be monitored by 0, 1 or several environmental monitoring programs.
Specific properties of "ObservedEvent"
The vector representation is modelled as a "GM_Object". This basically encompasses all types of geometric primitives.
It has also following attribute:
"magnitudeOrIntensity" which is modelled using the data type "LevelOrIntensity".
Specific properties of "ObservedEventCoverage"
In the related coverage representation, the values that vary over space (and therefore declared as the range of the coverage) are either the magnitude or intensity, or the likelihood of occurrence.
5.3.1.3. Consistency between spatial data sets
|
📕
|
IR Requirement
|
5.3.1.4. Identifier management
All key spatial object types (HazardArea, RiskZone, ExposedElement and ObservedEvent) shall be assigned an inspireID in accordance with the rules for Identifier Management defined in section 14 of D2.5 Generic Conceptual Model. The requirement for an inspireID follows Recommendation 27 from section 14 of D2.5:
From Section 14 of D2.5 Generic Conceptual Model |

|
The inspireID is required for those spatial objects to enable references from non-spatial resources to be established. The inspireID shall be a persistent, external object identifier. This means that the inspireID shall provide a consistent identifier enabling multiple non-spatial resources to be linked to the same object.
The identifier assigned as the inspireID shall follow the four requirements for external object identifiers:
-
Uniqueness: the identifier shall not be assigned to any other INSPIRE spatial object.
NOTE 1: Different versions of the spatial object shall have the same identifier
NOTE 2: Identifiers must not be re-used
-
Persistence: once assigned the identifier shall remain unchanged during the life-time of a spatial object
-
Traceability: a spatial object (or specific version) can be accessed based on its identifier
-
Feasibility: the system for defining identifiers has been designed to allow existing identifiers to be used
The inspireID contains three properties: localID, namespace and a «voidable» version. Where an INSPIRE Download Service provides access to multiple versions of spatial objects, the version parameter should be included to enable third parties to include the version of the spatial object when the referencing.
|
📘
|
Recomendation 7 It is strongly recommended that a version is included in the inspireId to allow different versions of a spatial object to be distinguished. |
5.3.1.5. Modelling of object references
In case that the spatial representation of an exposed element is defined and provided by another INSPIRE theme, the exposed element object shall reference that external object. The reference is made by instantiating the association link between "ExposedElement" and the abstract GML "AbstractFeature". This "AbstractFeature" encompasses any spatial object type of any INSPIRE data specifications. Object referencing is used to avoid any duplication of geometry between INSPIRE spatial objects.
|
📘
|
Recomendation 8 Member States and/or National Spatial Data Infrastructures should agree on the external information systems to share spatial objects that fulfill the definition of "ExposedElement" spatial object type. |
5.3.2. Feature catalogue
Feature catalogue metadata
Application Schema |
INSPIRE Application Schema NaturalRiskZones |
Version number |
3.0 |
Types defined in the feature catalogue
| Type | Package | Stereotypes |
|---|---|---|
AbstractExposedElement |
NaturalRiskZones |
«featureType» |
AbstractHazardArea |
NaturalRiskZones |
«featureType» |
AbstractObservedEvent |
NaturalRiskZones |
«featureType» |
AbstractRiskZone |
NaturalRiskZones |
«featureType» |
ExposedElement |
NaturalRiskZones |
«featureType» |
ExposedElementCategoryValue |
NaturalRiskZones |
«codeList» |
ExposedElementClassification |
NaturalRiskZones |
«dataType» |
ExposedElementCoverage |
NaturalRiskZones |
«featureType» |
HazardArea |
NaturalRiskZones |
«featureType» |
HazardCoverage |
NaturalRiskZones |
«featureType» |
LevelOrIntensity |
NaturalRiskZones |
«dataType» |
LikelihoodOfOccurrence |
NaturalRiskZones |
«dataType» |
NaturalHazardCategoryValue |
NaturalRiskZones |
«codeList» |
NaturalHazardClassification |
NaturalRiskZones |
«dataType» |
ObservedEvent |
NaturalRiskZones |
«featureType» |
ObservedEventCoverage |
NaturalRiskZones |
«featureType» |
QuantitativeLikelihood |
NaturalRiskZones |
«dataType» |
RiskCoverage |
NaturalRiskZones |
«featureType» |
RiskZone |
NaturalRiskZones |
«featureType» |
SpecificExposedElementTypeValue |
NaturalRiskZones |
«codeList» |
SpecificHazardTypeValue |
NaturalRiskZones |
«codeList» |
VulnerabilityAssessment |
NaturalRiskZones |
«dataType» |
5.3.2.1. Spatial object types
5.3.2.1.1. AbstractExposedElement
| AbstractExposedElement (abstract) | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: inspireId
|
||||||||
Attribute: beginLifeSpanVersion
|
||||||||
Attribute: endLifeSpanVersion
|
||||||||
Attribute: validFrom
|
||||||||
Attribute: validTo
|
||||||||
Association role: sourceOfSpatialRepresentation
|
||||||||
Constraint: If the "source of spatial representation" is empty, the geometry AbstractExposedElement spatial object shall be provided.
|
5.3.2.1.2. AbstractHazardArea
| AbstractHazardArea (abstract) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||
Attribute: beginLifeSpanVersion
|
||||||||||
Attribute: determinationMethod
|
||||||||||
Attribute: endLifeSpanVersion
|
||||||||||
Attribute: inspireId
|
||||||||||
Attribute: typeOfHazard
|
||||||||||
Attribute: validityPeriod
|
||||||||||
Association role: source
|
5.3.2.1.3. AbstractObservedEvent
| AbstractObservedEvent (abstract) | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: beginLifeSpanVersion
|
||||||||
Attribute: endLifeSpanVersion
|
||||||||
Attribute: inspireId
|
||||||||
Attribute: nameOfEvent
|
||||||||
Attribute: typeOfHazard
|
||||||||
Attribute: validFrom
|
||||||||
Attribute: validTo
|
||||||||
Association role: isMonitoredBy
|
5.3.2.1.4. AbstractRiskZone
| AbstractRiskZone (abstract) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||
Attribute: beginLifeSpanVersion
|
||||||||||
Attribute: endLifeSpanVersion
|
||||||||||
Attribute: inspireId
|
||||||||||
Attribute: sourceOfRisk
|
||||||||||
Attribute: validityPeriod
|
||||||||||
Association role: source
|
||||||||||
Association role: exposedElement
|
5.3.2.1.5. ExposedElementCoverage
| ExposedElementCoverage | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: typeOfElement
|
||||||||
Constraint: DomainisrectifedGridOrReferenceableGrid
|
||||||||
Constraint: Range set is the levelOfVulnerability of VulnerabilityAssessment
|
5.3.2.1.6. HazardCoverage
| HazardCoverage | ||||||
|---|---|---|---|---|---|---|
|
||||||
Constraint: DomainIsRectifiedGridOrReferenceableGrid
|
||||||
Constraint: RangeSet is levelOrIntensity, or likelihoodOfOccurrence
|
5.3.2.1.7. ObservedEventCoverage
| ObservedEventCoverage | ||||||
|---|---|---|---|---|---|---|
|
||||||
Constraint: DomainIsRectifiedGridOrReferenceableGrid
|
||||||
Constraint: RangeSet is levelOrIntensityOr LikelihoodOfOccurrence
|
5.3.2.1.8. RiskCoverage
| RiskCoverage | ||||||
|---|---|---|---|---|---|---|
|
||||||
Constraint: DomainIsRectifedGridOrReferenceableGrid
|
||||||
Constraint: Range set is levelOrIntensity
|
5.3.2.1.9. ObservedEvent
| ObservedEvent | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: geometry
|
||||||||
Attribute: magnitudeOrIntensity
|
5.3.2.1.10. HazardArea
| HazardArea | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||
Attribute: geometry
|
||||||||||
Attribute: likelihoodOfOccurrence
|
||||||||||
Attribute: magnitudeOrIntensity
|
5.3.2.1.11. RiskZone
| RiskZone | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: geometry
|
||||||||
Attribute: levelOfRisk
|
5.3.2.1.12. ExposedElement
| ExposedElement | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: geometry
|
||||||||
Attribute: assessmentOfVulnerability
|
5.3.2.2. Data types
5.3.2.2.1. VulnerabilityAssessment
| VulnerabilityAssessment | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||
Attribute: sourceOfVulnerability
|
||||||||||
Attribute: levelOfVulnerability
|
||||||||||
Attribute: magnitudeOrIntensityOfHazard
|
||||||||||
Attribute: typeOfElement
|
5.3.2.2.2. NaturalHazardClassification
| NaturalHazardClassification | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: hazardCategory
|
||||||||
Attribute: specificHazardType
|
5.3.2.2.3. LevelOrIntensity
| LevelOrIntensity | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: qualitativeValue
|
||||||||
Attribute: quantitativeValue
|
||||||||
Attribute: assessmentMethod
|
||||||||
Constraint: either the quantitative value or the qualitative value must be completed.
|
5.3.2.2.4. LikelihoodOfOccurrence
| LikelihoodOfOccurrence | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||
Attribute: qualitativeLikelihood
|
||||||||||
Attribute: quantitativeLikelihood
|
||||||||||
Attribute: assessmentMethod
|
||||||||||
Constraint: Either the qualitative likelihood or the quantitative likelihood must be completed.
|
5.3.2.2.5. QuantitativeLikelihood
| QuantitativeLikelihood | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||
Attribute: probabilityOfOccurrence
|
||||||||||
Attribute: returnPeriod
|
5.3.2.2.6. ExposedElementClassification
| ExposedElementClassification | ||||||||
|---|---|---|---|---|---|---|---|---|
|
||||||||
Attribute: exposedElementCategory
|
||||||||
Attribute: specificExposedElementType
|
5.3.2.3. Code lists
5.3.2.3.1. SpecificExposedElementTypeValue
| SpecificExposedElementTypeValue | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
5.3.2.3.2. SpecificHazardTypeValue
| SpecificHazardTypeValue | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
5.3.2.3.3. NaturalHazardCategoryValue
| NaturalHazardCategoryValue | ||||||||
|---|---|---|---|---|---|---|---|---|
|
5.3.2.3.4. ExposedElementCategoryValue
| ExposedElementCategoryValue | ||||||||
|---|---|---|---|---|---|---|---|---|
|
5.3.2.3.5. DeterminationMethodValue
| DeterminationMethodValue | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
5.3.2.4. Imported types (informative)
This section lists definitions for feature types, data types and code lists that are defined in other application schemas. The section is purely informative and should help the reader understand the feature catalogue presented in the previous sections. For the normative documentation of these types, see the given references.
5.3.2.4.1. AbstractFeature
| AbstractFeature (abstract) | ||||
|---|---|---|---|---|
|
5.3.2.4.2. CharacterString
| CharacterString | ||||
|---|---|---|---|---|
|
5.3.2.4.3. CoverageByDomainAndRange
| CoverageByDomainAndRange (abstract) | ||||||
|---|---|---|---|---|---|---|
|
5.3.2.4.4. DateTime
| DateTime | ||||
|---|---|---|---|---|
|
5.3.2.4.5. DocumentCitation
| DocumentCitation | ||||||
|---|---|---|---|---|---|---|
|
5.3.2.4.6. EnvironmentalMonitoringProgramme
| EnvironmentalMonitoringProgramme | ||||||
|---|---|---|---|---|---|---|
|
5.3.2.4.7. GM_Object
| GM_Object (abstract) | ||||
|---|---|---|---|---|
|
5.3.2.4.8. GM_Surface
| GM_Surface | ||||
|---|---|---|---|---|
|
5.3.2.4.9. Identifier
| Identifier | ||||||||
|---|---|---|---|---|---|---|---|---|
|
5.3.2.4.10. Measure
| Measure | ||||||
|---|---|---|---|---|---|---|
|
5.3.2.4.11. Number
| Number (abstract) | ||||
|---|---|---|---|---|
|
5.3.2.4.12. Probability
| Probability | ||||
|---|---|---|---|---|
|
5.3.2.4.13. TM_Period
| TM_Period | ||||
|---|---|---|---|---|
|
6. Reference systems, units of measure and grids
6.1. Default reference systems, units of measure and grid
The reference systems, units of measure and geographic grid systems included in this sub-section are the defaults to be used for all INSPIRE data sets, unless theme-specific exceptions and/or additional requirements are defined in section 6.2.
6.1.1. Coordinate reference systems
6.1.1.1. Datum
|
📕
|
IR Requirement For the three-dimensional and two-dimensional coordinate reference systems and the horizontal component of compound coordinate reference systems used for making spatial data sets available, the datum shall be the datum of the European Terrestrial Reference System 1989 (ETRS89) in areas within its geographical scope, or the datum of the International Terrestrial Reference System (ITRS) or other geodetic coordinate reference systems compliant with ITRS in areas that are outside the geographical scope of ETRS89. Compliant with the ITRS means that the system definition is based on the definition of the ITRS and there is a well documented relationship between both systems, according to EN ISO 19111. |
6.1.1.2. Coordinate reference systems
|
📕
|
IR Requirement Spatial data sets shall be made available using at least one of the coordinate reference systems specified in sections 1.3.1, 1.3.2 and 1.3.3, unless one of the conditions specified in section 1.3.4 holds. 1.3.1. Three-dimensional Coordinate Reference Systems
1.3.2. Two-dimensional Coordinate Reference Systems
1.3.3. Compound Coordinate Reference Systems
1.3.4. Other Coordinate Reference Systems Exceptions, where other coordinate reference systems than those listed in 1.3.1, 1.3.2 or 1.3.3 may be used, are:
The geodetic codes and parameters needed to describe these other coordinate reference systems and to allow conversion and transformation operations shall be documented and an identifier shall be created in a coordinate systems register established and operated by the Commission, according to EN ISO 19111 and ISO 19127. |
6.1.1.3. Display
|
📕
|
IR Requirement For the display of spatial data sets with the view network service as specified in Regulation No 976/2009, at least the coordinate reference systems for two-dimensional geodetic coordinates (latitude, longitude) shall be available. |
6.1.1.4. Identifiers for coordinate reference systems
|
📕
|
IR Requirement
|
These Technical Guidelines propose to use the http URIs provided by the Open Geospatial Consortium as coordinate reference system identifiers (see identifiers for the default CRSs in the INSPIRE coordinate reference systems register). These are based on and redirect to the definition in the EPSG Geodetic Parameter Registry (http://www.epsg-registry.org/).
|
📒
|
TG Requirement 2 The identifiers listed in the INSPIRE coordinate reference systems register (https://inspire.ec.europa.eu/crs) shall be used for referring to the coordinate reference systems used in a data set. |
NOTE CRS identifiers may be used e.g. in:
-
data encoding,
-
data set and service metadata, and
-
requests to INSPIRE network services.
6.1.2. Temporal reference system
|
📕
|
IR Requirement
|
NOTE 1 Point 5 of part B of the Annex to Commission Regulation (EC) No 1205/2008 (the INSPIRE Metadata IRs) states that the default reference system shall be the Gregorian calendar, with dates expressed in accordance with ISO 8601.
NOTE 2 ISO 8601 Data elements and interchange formats – Information interchange – Representation of dates and times is an international standard covering the exchange of date and time-related data. The purpose of this standard is to provide an unambiguous and well-defined method of representing dates and times, so as to avoid misinterpretation of numeric representations of dates and times, particularly when data is transferred between countries with different conventions for writing numeric dates and times. The standard organizes the data so the largest temporal term (the year) appears first in the data string and progresses to the smallest term (the second). It also provides for a standardized method of communicating time-based information across time zones by attaching an offset to Coordinated Universal Time (UTC).
EXAMPLE 1997 (the year 1997), 1997-07-16 (16th July 1997), 1997-07-16T19:20:3001:00 (16th July 1997, 19h 20' 30'', time zone: UTC1)
6.1.3. Units of measure
|
📕
|
IR Requirement (…)
|
6.1.4. Grids
|
📕
|
IR Requirement Either of the grids with fixed and unambiguously defined locations defined in Sections 2.2.1 and 2.2.2 shall be used as a geo-referencing framework to make gridded data available in INSPIRE, unless one of the following conditions holds:
2.2 Equal Area Grid The grid is based on the ETRS89 Lambert Azimuthal Equal Area (ETRS89-LAEA) coordinate reference system with the centre of the projection at the point 52o N, 10o E and false easting: x0 = 4321000 m, false northing: y0 = 3210000 m. The origin of the grid coincides with the false origin of the ETRS89-LAEA coordinate reference system (x=0, y=0). Grid points of grids based on ETRS89-LAEA shall coincide with grid points of the grid. The grid is hierarchical, with resolutions of 1m, 10m, 100m, 1000m, 10000m and 100000m. The grid orientation is south-north, west-east. The grid is designated as Grid_ETRS89-LAEA. For identification of an individual resolution level the cell size in metres is appended. For the unambiguous referencing and identification of a grid cell, the cell code composed of the size of the cell and the coordinates of the lower left cell corner in ETRS89-LAEA shall be used. The cell size shall be denoted in metres ("m") for cell sizes up to 100m or kilometres ("km") for cell sizes of 1000m and above. Values for northing and easting shall be divided by 10n, where n is the number of trailing zeros in the cell size value. |
6.2. Theme-specific requirements and recommendations
There are no theme-specific requirements or recommendations on reference systems and grids.
7. Data quality
This chapter includes a description of the data quality elements and sub-elements as well as the corresponding data quality measures that should be used to evaluate and document data quality for data sets related to the spatial data theme Natural Risk Zones (section 7.1).
It may also define requirements or recommendations about the targeted data quality results applicable for data sets related to the spatial data theme Natural Risk Zones (section 7.2).
In particular, the data quality elements, sub-elements and measures specified in section 7.1 should be used for
-
evaluating and documenting data quality properties and constraints of spatial objects, where such properties or constraints are defined as part of the application schema(s) (see section 5);
-
evaluating and documenting data quality metadata elements of spatial data sets (see section 8); and/or
-
specifying requirements or recommendations about the targeted data quality results applicable for data sets related to the spatial data theme Natural Risk Zones (see section 7.2).
The descriptions of the elements and measures are based on Annex D of ISO/DIS 19157 Geographic information – Data quality.
7.1. Data quality elements
Table 3 lists all data quality elements and sub-elements that are being used in this specification. Data quality information can be evaluated at level of spatial object, spatial object type, dataset or dataset series. The level at which the evaluation is performed is given in the "Evaluation Scope" column.
The measures to be used for each of the listed data quality sub-elements are defined in the following sub-sections.
Table 3 – Data quality elements used in the spatial data theme Natural Risk Zones
Section |
Data quality element |
Data quality sub-element |
Definition |
Evaluation Scope |
7.1.1 |
Logical consistency |
Conceptual consistency |
adherence to rules of the conceptual schema |
spatial object type; spatial object |
7.1.2 |
Logical consistency |
Domain consistency |
adherence of values to the value domains |
spatial object type; spatial object |
7.1.1. Logical consistency – Conceptual consistency
The Application Schema conformance class of the Abstract Test Suite in Annex I defines a number of tests to evaluate the conceptual consistency (tests A.1.1-A.1.9) of a data set The tests of the IR Theme-specific Requirements related to risk zones are also A.1.8 and A.1.9
|
📘
|
Recomendation 9 For the tests on conceptual consistency, it is recommended to use the Logical consistency – Conceptual consistency data quality sub-element and the measure Number of items not compliant with the rules of the conceptual schema as specified in the table below. |
Name |
|
Alternative name |
- |
Data quality element |
logical consistency |
Data quality sub-element |
conceptual consistency |
Data quality basic measure |
error count |
Definition |
count of all items in the dataset that are not compliant with the rules of the conceptual schema |
Description |
If the conceptual schema explicitly or implicitly describes rules, these rules shall be followed. Violations against such rules can be, for example, invalid placement of features within a defined tolerance, duplication of features and invalid overlap of features. |
Evaluation scope |
spatial object / spatial object type |
Reporting scope |
data set |
Parameter |
- |
Data quality value type |
integer |
Data quality value structure |
- |
Source reference |
ISO/DIS 19157 Geographic information – Data quality |
Example |
|
Measure identifier |
10 |
7.1.2. Logical consistency – Domain consistency
The Application Schema conformance class of the Abstract Test Suite in Annex I defines a number of tests to evaluate the domain consistency (tests A1.10-A.1.12) of a data set.
|
📘
|
Recomendation 10 For the tests on domain consistency, it is recommended to use the Logical consistency – Domain consistency data quality sub-element and the measure Number of items not in conformance with their value domain as specified in the table below. |
Name |
Number of items not in conformance with their value domain |
Alternative name |
- |
Data quality element |
logical consistency |
Data quality sub-element |
domain consistency |
Data quality basic measure |
error count |
Definition |
count of all items in the dataset that are not in conformance with their value domain |
Description |
|
Evaluation scope |
spatial object / spatial object type |
Reporting scope |
data set |
Parameter |
- |
Data quality value type |
integer |
7.2. Minimum data quality requirements
No minimum data quality requirements are defined.
8. Dataset-level metadata
This section specifies dataset-level metadata elements, which should be used for documenting metadata for a complete dataset or dataset series.
NOTE Metadata can also be reported for each individual spatial object (spatial object-level metadata). Spatial object-level metadata is fully described in the application schema(s) (section 5).
For some dataset-level metadata elements, in particular those for reporting data quality and maintenance, a more specific scope can be specified. This allows the definition of metadata at sub-dataset level, e.g. separately for each spatial object type (see instructions for the relevant metadata element).
8.1. Metadata elements defined in INSPIRE Metadata Regulation
Table 4 gives an overview of the metadata elements specified in Regulation 1205/2008/EC (implementing Directive 2007/2/EC of the European Parliament and of the Council as regards metadata).
The table contains the following information:
-
The first column provides a reference to the relevant section in the Metadata Regulation, which contains a more detailed description.
-
The second column specifies the name of the metadata element.
-
The third column specifies the multiplicity.
-
The fourth column specifies the condition, under which the given element becomes mandatory.
Table 4 – Metadata for spatial datasets and spatial dataset series specified in Regulation 1205/2008/EC
Metadata Regulation Section |
Metadata element |
Multiplicity |
Condition |
1.1 |
Resource title |
1 |
|
1.2 |
Resource abstract |
1 |
|
1.3 |
Resource type |
1 |
|
1.4 |
Resource locator |
0..* |
Mandatory if a URL is available to obtain more information on the resource, and/or access related services. |
1.5 |
Unique resource identifier |
1..* |
|
1.7 |
Resource language |
0..* |
Mandatory if the resource includes textual information. |
2.1 |
Topic category |
1..* |
|
3 |
Keyword |
1..* |
|
4.1 |
Geographic bounding box |
1..* |
|
5 |
Temporal reference |
1..* |
|
6.1 |
Lineage |
1 |
|
6.2 |
Spatial resolution |
0..* |
Mandatory for data sets and data set series if an equivalent scale or a resolution distance can be specified. |
7 |
Conformity |
1..* |
|
8.1 |
Conditions for access and use |
1..* |
|
8.2 |
Limitations on public access |
1..* |
|
9 |
Responsible organisation |
1..* |
|
10.1 |
Metadata point of contact |
1..* |
|
10.2 |
Metadata date |
1 |
|
10.3 |
Metadata language |
1 |
Generic guidelines for implementing these elements using ISO 19115 and 19119 are available at https://knowledge-base.inspire.ec.europa.eu/publications/technical-guidance-implementation-inspire-dataset-and-service-metadata-based-isots-191392007_en. The following sections describe additional theme-specific recommendations and requirements for implementing these elements.
8.1.1. Conformity
The Conformity metadata element defined in Regulation 1205/2008/EC requires to report the conformance with the Implementing Rule for interoperability of spatial data sets and services. In addition, it may be used also to document the conformance to another specification.
|
📘
|
Recomendation 11 Dataset metadata should include a statement on the overall conformance of the dataset with this data specification (i.e. conformance with all requirements). |
|
📘
|
Recomendation 12 The Conformity metadata element should be used to document conformance with this data specification (as a whole), with a specific conformance class defined in the Abstract Test Suite in Annex A and/or with another specification. |
The Conformity element includes two sub-elements, the Specification (a citation of the Implementing Rule for interoperability of spatial data sets and services or other specification), and the Degree of conformity. The Degree can be Conformant (if the dataset is fully conformant with the cited specification), Not Conformant (if the dataset does not conform to the cited specification) or Not Evaluated (if the conformance has not been evaluated).
|
📘
|
Recomendation 13 If a dataset is not yet conformant with all requirements of this data specification, it is recommended to include information on the conformance with the individual conformance classes specified in the Abstract Test Suite in Annex A. |
|
📘
|
Recomendation 14 If a dataset is produced or transformed according to an external specification that includes specific quality assurance procedures, the conformity with this specification should be documented using the Conformity metadata element. |
|
📘
|
Recomendation 15 If minimum data quality recommendations are defined then the statement on the conformity with these requirements should be included using the Conformity metadata element and referring to the relevant data quality conformance class in the Abstract Test Suite. |
NOTE Currently no minimum data quality requirements are included in the IRs. The recommendation above should be included as a requirement in the IRs if minimum data quality requirements are defined at some point in the future.
|
📘
|
Recomendation 16 When documenting conformance with this data specification or one of the conformance classes defined in the Abstract Test Suite, the Specification sub-element should be given using the http URI identifier of the conformance class or using a citation including the following elements:
|
EXAMPLE 1: The XML snippets below show how to fill the Specification sub-element for documenting conformance with the whole data specification on Addresses v3.0.1.
<gmd:DQ_ConformanceResult>
<gmd:specification href="http://inspire.ec.europa.eu/conformanceClass/ad/3.0.1/tg" />
<gmd:explanation> (...) </gmd:explanation>
<gmd:pass> (...) </gmd:pass>
</gmd:DQ_ConformanceResult>or (using a citation):
<gmd:DQ_ConformanceResult>
<gmd:specification>
<gmd:CI_Citation>
<gmd:title>
<gco:CharacterString>INSPIRE Data Specification on Natural Risk Zones – Technical Guidelines</gco:CharacterString>
</gmd:title>
<gmd:date>
<gmd:date>
<gco:Date>2013-01-29</gco:Date>
</gmd:date>
<gmd:dateType>
<gmd:CI_DateTypeCode codeList="http://standards.iso.org/ittf/PubliclyAvailableStandards/ISO_19139_Schemas/resou
rces/Codelist/ML_gmxCodelists.xml#CI_DateTypeCode" codeListValue="publication">publication</gmd:CI_DateTypeCode>
</gmd:dateType>
</gmd:date>
</gmd:CI_Citation>
</gmd:specification>
<gmd:explanation> (...) </gmd:explanation>
<gmd:pass> (...) </gmd:pass>
</gmd:DQ_ConformanceResult>EXAMPLE 2: The XML snippets below show how to fill the Specification sub-element for documenting conformance with the CRS conformance class of the data specification on Addresses v3.0.1.
<gmd:DQ_ConformanceResult>
<gmd:specification href="http://inspire.ec.europa.eu/conformanceClass/ad/3.0.1/crs" />
<gmd:explanation> (...) </gmd:explanation>
<gmd:pass> (...) </gmd:pass>
</gmd:DQ_ConformanceResult>or (using a citation):
<gmd:DQ_ConformanceResult>
<gmd:specification>
<gmd:CI_Citation>
<gmd:title>
<gco:CharacterString>INSPIRE Data Specification on Natural Risk Zones – Technical Guidelines – CRS</gco:CharacterString>
</gmd:title>
<gmd:date>
<gmd:date>
<gco:Date>2013-01-29</gco:Date>
</gmd:date>
<gmd:dateType>
<gmd:CI_DateTypeCode codeList="http://standards.iso.org/ittf/PubliclyAvailableStandards/ISO_19139_Schemas/resou
rces/Codelist/ML_gmxCodelists.xml#CI_DateTypeCode" codeListValue="publication">publication</gmd:CI_DateTypeCode>
</gmd:dateType>
</gmd:date>
</gmd:CI_Citation>
</gmd:specification>
<gmd:explanation> (...) </gmd:explanation>
<gmd:pass> (...) </gmd:pass>
</gmd:DQ_ConformanceResult>8.1.2. Lineage
|
📘
|
Recomendation 17 Following the ISO/DIS 19157 Quality principles, if a data provider has a procedure for the quality management of their spatial data sets then the appropriate data quality elements and measures defined in ISO/DIS 19157 should be used to evaluate and report (in the metadata) the results. If not, the Lineage metadata element (defined in Regulation 1205/2008/EC) should be used to describe the overall quality of a spatial data set. |
According to Regulation 1205/2008/EC, lineage "is a statement on process history and/or overall quality of the spatial data set. Where appropriate it may include a statement whether the data set has been validated or quality assured, whether it is the official version (if multiple versions exist), and whether it has legal validity. The value domain of this metadata element is free text".
The Metadata Technical Guidelines based on EN ISO 19115 and EN ISO 19119 specifies that the statement sub-element of LI_Lineage (EN ISO 19115) should be used to implement the lineage metadata element.
|
📘
|
Recomendation 18 To describe the transformation steps and related source data, it is recommended to use the following sub-elements of LI_Lineage:
|
NOTE 1 In order to improve the interoperability, domain templates and instructions for using these free text elements (descriptive statements) may be specified here and/or in an Annex of this data specification.
|
📘
|
Recomendation 19 If the geometries of the exposed elements data set are derived from the geometries of spatial objects in another data set, then this source data set (including its version) shall be described as part (LI_Source) of the lineage metadata element. |
8.1.3. Temporal reference
According to Regulation 1205/2008/EC, at least one of the following temporal reference metadata sub-elements shall be provided: temporal extent, date of publication, date of last revision, date of creation.
|
📘
|
Recomendation 20 It is recommended that at least the date of the last revision of a spatial data set should be reported using the Date of last revision metadata sub-element. |
8.2. Metadata elements for interoperability
|
📕
|
IR Requirement The metadata describing a spatial data set shall include the following metadata elements required for interoperability:
|
These Technical Guidelines propose to implement the required metadata elements based on ISO 19115 and ISO/TS 19139.
The following TG requirements need to be met in order to be conformant with the proposed encoding.
|
📒
|
TG Requirement 3 Metadata instance (XML) documents shall validate without error against the used ISO 19139 XML schema. |
NOTE Section 2.1.2 of the Metadata Technical Guidelines discusses the different ISO 19139 XML schemas that are currently available.
|
📒
|
TG Requirement 4 Metadata instance (XML) documents shall contain the elements and meet the INSPIRE multiplicity specified in the sections below. |
|
📒
|
TG Requirement 5 The elements specified below shall be available in the specified ISO/TS 19139 path. |
|
📘
|
Recomendation 21 The metadata elements for interoperability should be made available together with the metadata elements defined in the Metadata Regulation through an INSPIRE discovery service. |
NOTE While this not explicitly required by any of the INSPIRE Implementing Rules, making all metadata of a data set available together and through one service simplifies implementation and usability.
8.2.1. Coordinate Reference System
Metadata element name |
Coordinate Reference System |
Definition |
Description of the coordinate reference system used in the dataset. |
ISO 19115 number and name |
13. referenceSystemInfo |
ISO/TS 19139 path |
referenceSystemInfo |
INSPIRE obligation / condition |
mandatory |
INSPIRE multiplicity |
1..* |
Data type(and ISO 19115 no.) |
186. MD_ReferenceSystem |
Domain |
To identify the reference system, the referenceSystemIdentifier (RS_Identifier) shall be provided. NOTE More specific instructions, in particular on pre-defined values for filling the referenceSystemIdentifier attribute should be agreed among Member States during the implementation phase to support interoperability. |
Implementing instructions |
|
Example |
referenceSystemIdentifier: |
Example XML encoding |
|
Comments |
8.2.2. Temporal Reference System
Metadata element name |
Temporal Reference System |
Definition |
Description of the temporal reference systems used in the dataset. |
ISO 19115 number and name |
13. referenceSystemInfo |
ISO/TS 19139 path |
referenceSystemInfo |
INSPIRE obligation / condition |
Mandatory, if the spatial data set or one of its feature types contains temporal information that does not refer to the Gregorian Calendar or the Coordinated Universal Time. |
INSPIRE multiplicity |
0..* |
Data type(and ISO 19115 no.) |
186. MD_ReferenceSystem |
Domain |
No specific type is defined in ISO 19115 for temporal reference systems. Thus, the generic MD_ReferenceSystem element and its reference SystemIdentifier (RS_Identifier) property shall be provided. NOTE More specific instructions, in particular on pre-defined values for filling the referenceSystemIdentifier attribute should be agreed among Member States during the implementation phase to support interoperability. |
Implementing instructions |
|
Example |
referenceSystemIdentifier: |
Example XML encoding |
|
Comments |
8.2.3. Encoding
Metadata element name |
Encoding |
Definition |
Description of the computer language construct that specifies the representation of data objects in a record, file, message, storage device or transmission channel |
ISO 19115 number and name |
271. distributionFormat |
ISO/TS 19139 path |
distributionInfo/MD_Distribution/distributionFormat |
INSPIRE obligation / condition |
mandatory |
INSPIRE multiplicity |
1..* |
Data type (and ISO 19115 no.) |
284. MD_Format |
Domain |
See B.2.10.4. The property values (name, version, specification) specified in section 5 shall be used to document the default and alternative encodings. |
Implementing instructions |
|
Example |
name: <Application schema name> GML application schema |
Example XML encoding |
|
Comments |
8.2.4. Character Encoding
Metadata element name |
Character Encoding |
Definition |
The character encoding used in the data set. |
ISO 19115 number and name |
|
ISO/TS 19139 path |
|
INSPIRE obligation / condition |
Mandatory, if an encoding is used that is not based on UTF-8. |
INSPIRE multiplicity |
0..* |
Data type (and ISO 19115 no.) |
|
Domain |
|
Implementing instructions |
|
Example |
- |
Example XML encoding |
|
Comments |
8.2.5. Spatial representation type
Metadata element name |
Spatial representation type |
Definition |
The method used to spatially represent geographic information. |
ISO 19115 number and name |
37. spatialRepresentationType |
ISO/TS 19139 path |
|
INSPIRE obligation / condition |
Mandatory |
INSPIRE multiplicity |
1..* |
Data type (and ISO 19115 no.) |
B.5.26 MD_SpatialRepresentationTypeCode |
Domain |
|
Implementing instructions |
Of the values included in the code list in ISO 19115 (vector, grid, textTable, tin, stereoModel, video), only vector, grid and tin should be used. NOTE Additional code list values may be defined based on feedback from implementation. |
Example |
- |
Example XML encoding |
|
Comments |
8.2.6. Data Quality – Logical Consistency – Topological Consistency
See section 8.3.2 for instructions on how to implement metadata elements for reporting data quality.
8.3. Recommended theme-specific metadata elements
|
📘
|
Recomendation 22 The metadata describing a spatial data set or a spatial data set series related to the theme Natural Risk Zones should comprise the theme-specific metadata elements specified in Table 5. |
The table contains the following information:
-
The first column provides a reference to a more detailed description.
-
The second column specifies the name of the metadata element.
-
The third column specifies the multiplicity.
Table 5 – Optional theme-specific metadata elements for the theme Natural Risk Zones
| Section | Metadata element | Multiplicity |
|---|---|---|
8.3.1 |
Maintenance Information |
0..1 |
8.3.2 |
Logical Consistency – Conceptual Consistency |
0..* |
8.3.2 |
Logical Consistency – Domain Consistency |
0..* |
|
📘
|
Recomendation 23 For implementing the metadata elements included in this section using ISO 19115, ISO/DIS 19157 and ISO/TS 19139, the instructions included in the relevant sub-sections should be followed. |
8.3.1. Maintenance Information
Metadata element name |
Maintenance information |
Definition |
Information about the scope and frequency of updating |
ISO 19115 number and name |
30. resourceMaintenance |
ISO/TS 19139 path |
identificationInfo/MD_Identification/resourceMaintenance |
INSPIRE obligation / condition |
optional |
INSPIRE multiplicity |
0..1 |
Data type(and ISO 19115 no.) |
142. MD_MaintenanceInformation |
Domain |
This is a complex type (lines 143-148 from ISO 19115). At least the following elements should be used (the multiplicity according to ISO 19115 is shown in parentheses):
|
Implementing instructions |
|
Example |
|
Example XML encoding |
|
Comments |
8.3.2. Metadata elements for reporting data quality
|
📘
|
Recomendation 24 For reporting the results of the data quality evaluation, the data quality elements, sub-elements and (for quantitative evaluation) measures defined in chapter 7 should be used. |
|
📘
|
Recomendation 25 The metadata elements specified in the following sections should be used to report the results of the data quality evaluation. At least the information included in the row "Implementation instructions" should be provided. |
The first section applies to reporting quantitative results (using the element DQ_QuantitativeResult), while the second section applies to reporting non-quantitative results (using the element DQ_DescriptiveResult).
|
📘
|
Recomendation 26 If a dataset does not pass the tests of the Application schema conformance class (defined in Annex A), the results of each test should be reported using one of the options described in sections 8.3.2.1 and 8.3.2.2. |
NOTE 1 If using non-quantitative description, the results of several tests do not have to be reported separately, but may be combined into one descriptive statement.
NOTE 2 The sections 8.3.2.1 and 8.3.2.2 may need to be updated once the XML schemas for ISO 19157 have been finalised.
The scope for reporting may be different from the scope for evaluating data quality (see section 7). If data quality is reported at the data set or spatial object type level, the results are usually derived or aggregated.
|
📘
|
Recomendation 27 The scope element (of type DQ_Scope) of the DQ_DataQuality subtype should be used to encode the reporting scope. Only the following values should be used for the level element of DQ_Scope: Series, Dataset, featureType. If the level is featureType the levelDescription/MDScopeDescription/features element (of type Set< GF_FeatureType>) shall be used to list the feature type names. |
NOTE In the level element of DQ_Scope, the value featureType is used to denote spatial object type.
8.3.2.1. Guidelines for reporting quantitative results of the data quality evaluation
Metadata element name |
See chapter 7 |
Definition |
See chapter 7 |
ISO/DIS 19157 number and name |
3. report |
ISO/TS 19139 path |
dataQualityInfo/*/report |
INSPIRE obligation / condition |
optional |
INSPIRE multiplicity |
0..* |
Data type (and ISO/DIS 19157 no.) |
Corresponding DQ_xxx subelement from ISO/DIS 19157, e.g. 12. DQ_CompletenessCommission |
Domain |
Lines 7-9 from ISO/DIS 19157
|
Implementing instructions |
NOTE This should be the name as defined in Chapter 7.
NOTE If the reported data quality results are derived or aggregated (i.e. the scope levels for evaluation and reporting are different), the derivation or aggregation should also be specified using this property.
NOTE This should be data or range of dates on which the data quality measure was applied.
NOTE The DQ_Result type should be DQ_QuantitativeResult and the value(s) represent(s) the application of the data quality measure (39.) using the specified evaluation method (42-43.) |
Example |
See Table E.12 — Reporting commission as metadata (ISO/DIS 19157) |
Example XML encoding |
8.3.2.2. Guidelines for reporting descriptive results of the Data Quality evaluation
Metadata element name |
See chapter 7 |
Definition |
See chapter 7 |
ISO/DIS 19157 number and name |
3. report |
ISO/TS 19139 path |
dataQualityInfo/*/report |
INSPIRE obligation / condition |
optional |
INSPIRE multiplicity |
0..* |
Data type (and ISO/DIS 19157 no.) |
Corresponding DQ_xxx subelement from ISO/DIS 19157, e.g. 12. DQ_CompletenessCommission |
Domain |
Line 9 from ISO/DIS 19157
|
Implementing instructions |
NOTE The DQ_Result type should be DQ_DescriptiveResult and in the statement (68.) the evaluation of the selected DQ sub-element should be expressed in a narrative way. |
Example |
See Table E.15 — Reporting descriptive result as metadata (ISO/DIS 19157) |
Example XML encoding |
9. Delivery
9.1. Updates
|
📕
|
IR Requirement
|
NOTE In this data specification, no exception is specified, so all updates shall be made available at the latest 6 months after the change was applied in the source data set.
9.2. Delivery medium
According to Article 11(1) of the INSPIRE Directive, Member States shall establish and operate a network of services for INSPIRE spatial data sets and services. The relevant network service types for making spatial data available are:
-
view services making it possible, as a minimum, to display, navigate, zoom in/out, pan, or overlay viewable spatial data sets and to display legend information and any relevant content of metadata;
-
download services, enabling copies of spatial data sets, or parts of such sets, to be downloaded and, where practicable, accessed directly;
-
transformation services, enabling spatial data sets to be transformed with a view to achieving interoperability.
NOTE For the relevant requirements and recommendations for network services, see the relevant Implementing Rules and Technical Guidelines[15].
EXAMPLE 1 Through the Get Spatial Objects function, a download service can either download a pre-defined data set or pre-defined part of a data set (non-direct access download service), or give direct access to the spatial objects contained in the data set, and download selections of spatial objects based upon a query (direct access download service). To execute such a request, some of the following information might be required:
-
the list of spatial object types and/or predefined data sets that are offered by the download service (to be provided through the Get Download Service Metadata operation),
-
and the query capabilities section advertising the types of predicates that may be used to form a query expression (to be provided through the Get Download Service Metadata operation, where applicable),
-
a description of spatial object types offered by a download service instance (to be provided through the Describe Spatial Object Types operation).
EXAMPLE 2 Through the Transform function, a transformation service carries out data content transformations from native data forms to the INSPIRE-compliant form and vice versa. If this operation is directly called by an application to transform source data (e.g. obtained through a download service) that is not yet conformant with this data specification, the following parameters are required:
Input data (mandatory). The data set to be transformed.
-
Source model (mandatory, if cannot be determined from the input data). The model in which the input data is provided.
-
Target model (mandatory). The model in which the results are expected.
-
Model mapping (mandatory, unless a default exists). Detailed description of how the transformation is to be carried out.
9.3. Encodings
The IRs contain the following two requirements for the encoding to be used to make data available.
|
📕
|
IR Requirement 1. Every encoding rule used to encode spatial data shall conform to EN ISO 19118. In particular, it shall specify schema conversion rules for all spatial object types and all attributes and association roles and the output data structure used. 2. Every encoding rule used to encode spatial data shall be made available. 2a. Every encoding rule used to encode spatial data shall also specify whether and how to represent attributes and association roles for which a corresponding value exists but is not contained in the spatial data sets maintained by a Member State, or cannot be derived from existing values at reasonable costs. |
NOTE ISO 19118:2011 specifies the requirements for defining encoding rules used for interchange of geographic data within the set of International Standards known as the "ISO 19100 series". An encoding rule allows geographic information defined by application schemas and standardized schemas to be coded into a system-independent data structure suitable for transport and storage. The encoding rule specifies the types of data being coded and the syntax, structure and coding schemes used in the resulting data structure. Specifically, ISO 19118:2011 includes
-
requirements for creating encoding rules based on UML schemas,
-
requirements for creating encoding services, and
-
requirements for XML-based encoding rules for neutral interchange of data.
While the IRs do not oblige the usage of a specific encoding, these Technical Guidelines propose to make data related to the spatial data theme Natural Risk Zones available at least in the default encoding(s) specified in section 0. In this section, a number of TG requirements are listed that need to be met in order to be conformant with the default encoding(s).
The proposed default encoding(s) meet the requirements in Article 7 of the IRs, i.e. they are conformant with ISO 19118 and (since they are included in this specification) publicly available.
9.3.1. Default Encoding(s)
9.3.1.1. Specific requirements for GML encoding
This data specification proposes the use of GML as the default encoding, as recommended in sections 7.2 and 7.3 of [DS-D2.7]. GML is an XML encoding in compliance with ISO 19118, as required in Article 7(1). For details, see [ISO 19136], and in particular Annex E (UML-to-GML application schema encoding rules).
The following TG requirements need to be met in order to be conformant with GML encodings.
|
📒
|
TG Requirement 6 Data instance (XML) documents shall validate without error against the provided XML schema. |
NOTE 1 Not all constraints defined in the application schemas can be mapped to XML. Therefore, the following requirement is necessary.
NOTE 2 The obligation to use only the allowed code list values specified for attributes and most of the constraints defined in the application schemas cannot be mapped to the XML sch. They can therefore not be enforced through schema validation. It may be possible to express some of these constraints using other schema or rule languages (e.g. Schematron), in order to enable automatic validation.
9.3.1.2. Default encoding(s) for application schema NaturalRiskZones
Name: NaturalRiskZones GML Application Schema
Version: 5.0
Specification: D2.8.III.12 Data Specification on Natural Risk Zones - Technical Guidelines
Character set: UTF-8
The xml schema document is available on the INSPIRE website https://inspire.ec.europa.eu/schemas/nz-core/5.0/NaturalRiskZonesCore.xsd
9.4. Options for delivering coverage data
For coverages, different encodings may be used for the domain and the range of the coverage. There are several options for packaging the domain and range encoding when delivering coverage data through a download service, as discussed below[16].].
Multipart representation
For performance reasons, binary file formats are usually preferred to text-based formats such as XML for storing large amounts of coverage data. However, they cannot directly constitute an alternative to pure GML, since their own data structure might often not support all the ISO 19123 elements used to describe coverages in the conceptual model.
The OGC standard GML Application Schema for coverages [OGC 09-146r2] offers a format encoding which combines these two approaches. The first part consists of a GML document representing all coverage components except the range set, which is contained in the second part in some other encoding format such as 'well known' binary formats'. Some information in the second part may be redundant with the GML content of the first part. In this case, consistency must be necessarily ensured, for example by defining a GML mapping of the additional encoding format.
The advantage of this multipart representation is that coverage constituents are not handled individually but as a whole. This is not really the case with GML which also allows the encoding of the value side of the coverage in external binary files, but via references to remote locations.
|
📒
|
TG Requirement 7 Coverage data encoded as multipart messages shall comply with the multipart representation conformance class defined in GML Application Schema for Coverages [OGC 09-146r2]. |
NOTE The GML Application Schema for Coverages establishes a one-to-one relationship between coverages and multipart document instances.
Reference to an external file
The range set can be encoded within the XML structure as an external binary file using the gml:File element. This has the benefit of efficiently storing the range set data within an external file that is of a well-known format type, for example TIFF or GeoTIFF. This method of encoding is of most use for the storage of large files.
Encoding the range inline
This option encodes the range set data within the XML inline. This is encoded as a DataBlock element. This encoding provides much greater visibility for the range set values, however, this comes at the cost of reduced efficiency. This method of encoding would therefore only be suitable for small datasets.
Encoding the domain inside a JPEG 2000 file
This option consists in packaging all the components of one or several coverages, including the domain expressed in GML, in a single JPEG 2000 file. It is based on the OGC standard GML in JPEG 2000 for Geographic Imagery [OGC 05-047r2], also known as GMLJP2, which specifies how to use GML within the XML boxes of JPEG 2000 files.
|
📒
|
TG Requirement 8 Coverage data encoded in standalone JPEG 2000 files shall comply with the OGC standard GML in JPEG 2000 for Geographic Imagery [OGC 05-047r2]. |
TG Requirement 8 implies that all the encoding rules presented in GMLJP2 shall be strictly followed for including GML within JPEG 2000 data files correctly. For the sake of harmonization, the encoding rules adopted for the multipart message encoding should also apply to the GMLJP2 encoding.
The encoding of coverage components in GMLJP2 within a JPEG 2000 file should conform to the rules specified in the Guidelines for the encoding of spatial data [DS-D2.7].
9.4.1. Optional encoding for the coverage part of the application schema NaturalRiskZones.
For Hazard Areas, Risk Zones, Exposed Elements and Observed Events spatial object types that are presented as coverages the following encodings are recommended:
|
📘
|
Recomendation 1 The recommended coverage encodings for HazardAreaCoverage, RiskZoneCoverage, ExposedElementCoverage and ObservedEventCoverage spatial object types are: GeoTIFF and JPEG2000. |
The encoding of coverage components in GMLJP2 within a JPEG 2000 file should conform to the rules specified in the Guidelines for the encoding of spatial data [DS-D2.7]
10. Data Capture
There is no specific guidance required with respect to data capture.
11. Portrayal
This clause defines the rules for layers and styles to be used for portrayal of the spatial object types defined for this theme. Portrayal is regulated in Article 14 of the IRs.
|
📕
|
IR Requirement
|
In section , the types of layers are defined that are to be used for the portrayal of the spatial object types defined in this specification. A view service may offer several layers of the same type, one for each dataset that it offers data on a specific topic.
NOTE The layer specification in the IRs only contains the name, a human readable title and the (subset(s) of) spatial object type(s), that constitute(s) the content of the layer. In addition, these Technical Guidelines suggest keywords for describing the layer.
|
📘
|
Recomendation 28 It is recommended to use the keywords specified in section in the Layers Metadata parameters of the INSPIRE View service (see Annex III, Part A, section 2.2.4 in Commission Regulation (EC) No 976/2009). |
Section 11.1.1 specifies one style for each of these layers. It is proposed that INSPIRE view services support this style as the default style required by Article 14(1b).
|
📒
|
TG Requirement 9 For each layer specified in this section, the styles defined in section 11.1 shall be available. |
NOTE The default style should be used for portrayal by the view network service if no user-defined style is specified in a portrayal request for a specific layer.
In section 11.2, further styles can be specified that represent examples of styles typically used in a thematic domain. It is recommended that also these styles should be supported by INSPIRE view services, where applicable.
|
📘
|
Recomendation 29 In addition, it is recommended that, where applicable, INSPIRE view services also support the styles defined in section 11.2. |
Where XML fragments are used in the following sections, the following namespace prefixes apply:
-
sld="http://www.opengis.net/sld" (WMS/SLD 1.1)
-
se="http://www.opengis.net/se" (SE 1.1)
-
ogc="http://www.opengis.net/ogc" (FE 1.1)
11.1. Layers to be provided by INSPIRE view services
| Layer Name | Layer Title | Spatial object type(s) | Keywords |
|---|---|---|---|
NZ.RiskZone |
Risk Zones |
RiskZone |
Flood, forest fire, earthquake, landslide, etc. |
NZ.RiskZoneCoverage |
Risk Zones Coverage |
RiskZoneCoverage |
|
<human readable name> Example: Landslides |
HazardArea, HazardAreaCoverage (typeOfHazard: NaturalHazardCategoryValue) |
||
<human readable name> Example: Floods |
ObservedEvent, ObservedEventCoverage (typeOfHazard: NaturalHazardCategoryValue) |
||
NZ.ExposedElement |
Exposed Elements |
ExposedElement |
Buildings, people, urban areas, hospitals, roads, etc. etc |
NZ.ExposedElementCoverage |
Exposed Element Coverage |
ExposedElementCoverage |
NOTE The table above contains several layers for the spatial object type(s), which can be further classified using a code list-valued attribute. Such sets of layers are specified as described in Article 14(3) of the IRs.
|
📕
|
IR Requirement (…)
|
11.1.1. Layers organisation
None.
11.2. Styles recommended to be supported by INSPIRE view services
The Natural Risk Zones Theme includes definitions of layers (see section 11.1.) that represent all major spatial object types (concepts) including vector and coverage forms defined in this Technical Guidelines. They also cover major data provider categories (Risk data providers, Natural hazard type providers etc.) the current practise of data provision in this domain. However since the scope of this data specification is very large covering several natural hazard domains (e.g. floods, forest fires, landslides, etc.) it is impossible to define required – mandatory styles for displaying the data for each domain. Figure 10 shows an example of representation schema used in France for flood risk and hazard mapping. It is noticeable that the figure is one example for one hazard type and for one country. Hence a large number of options emerge when considering all the natural hazard and country approaches used in Europe. The aim of this chapter is therefore provide portrayal recommendations for all defined Layers that should be simple and applicable and represent the best practices in the different natural hazard/risk domains. Nevertheless, the chapter describes, by means of examples, best practices followed in several natural hazard domains.
Figure 10: Representation styles for flood risk and hazard mapping
The Representation styles in Figure 10 from the Environmental Ministry of France17 (source: Elaboration d’une base de données géographique pour la cartographie des zones inondables / guide de numérisation des objets géographiques. Direction de la Prévention des pollutions et des risques, February, 2002).
11.2.1. Styles for the layer NZ.RiskZone and NZ.HazardArea
This chapter is applicable both for risk zones and hazard areas. The risk zones and the hazard areas are either polygons or grid cells in the case of coverages. Risk zones should be portrayed according to the values taken for the attributes "sourceOfRisk" and "levelOfRisk". And Hazard areas according to "typeOfHazard" and "magnitudeOrIntensity".
When using a dataset that details the level of risk or magnitude of hazard over a certain area for one type of risk or hazard the attribute "levelOfRisk" ("magnitudeOrIntensity" in the case of hazards) has the information to be represented. It is either a qualitative or a quantitative concept. It is recommended that risk zones and hazard areas are portrayed with a classification: this requires no work when the level of risk or magnitude of hazard is assessed qualitatively (when the "QualitativeValue" attribute is completed). When the level of risk or magnitude of hazard is assessed quantitatively (when the "QuantitativeValue" attribute is completed), the user must set some classes depending upon a range of values. For this latter case, it is recommended to set no more than 5 classes. The classes should be portrayed using shaded tones of colours.
11.2.2. Styles for the layer NZ.RiskZone
| Style Name | NZ.RiskZone |
|---|---|
Style Title |
Level of Risk |
Style Abstract |
This style is for the representation of risk levels data as polygons or grid cells (coverage). The risk categories are usually represented using a colour ramp from clear to darker (low risk to high risk) depending on the attribute included in "levelOfRisk". The example below shows a coastal flood risk map from The Netherlands. |
Symbology |
Example of portrayal layer of the "sourceOfRisk" floods: coastal flood risk map (source: Safecoast Action 3A, Trends in Flood Risk, July 2008: 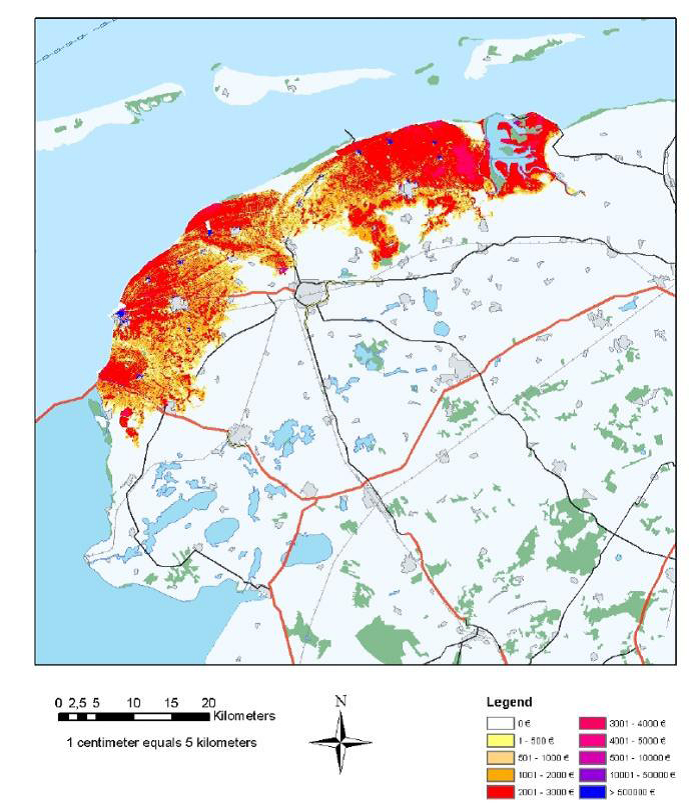
Example of portrayal layer of the "sourceOfRisk" landslides (source: Lekkas, E. (2009) Landslide hazard and risk in geologically active areas. The case of the caldera of Santorini (Thera) volcano island complex (Greece). International Association for Engineering Geology (IAEG), 7th Asian Regional Conference for IAEG, pp. 417-423, Chengdu. 

|
Symbology SLD |
The symbology is specified in the file: UserStyle_NZ_RiskZone.xml |
Minimum & maximum scales |
No scale limits |
11.2.3. Styles for the layer NZ.HazardArea
| Style Name | NZ.HazardArea |
|---|---|
Style Title |
"magnitudeOrIntensity" of the type of hazard |
Style Abstract |
This style is for the representation of hazard levels data as polygons or grid cells (coverage). The hazard categories are usually represented using a colour ramp from clear to darker (low to high hazard) depending on the attribute included in "magnitudeOrIntensity". The example below shows a forest fire hazard map (coverage) and a flood hazard map (feature). |
Symbology |
Example of portrayal of layer for the "typeOfHazard" forest fire (source: European Forest Fire Information System: Forest danger forecast. http://effis.jrc.ec.europa.eu/current-situation) 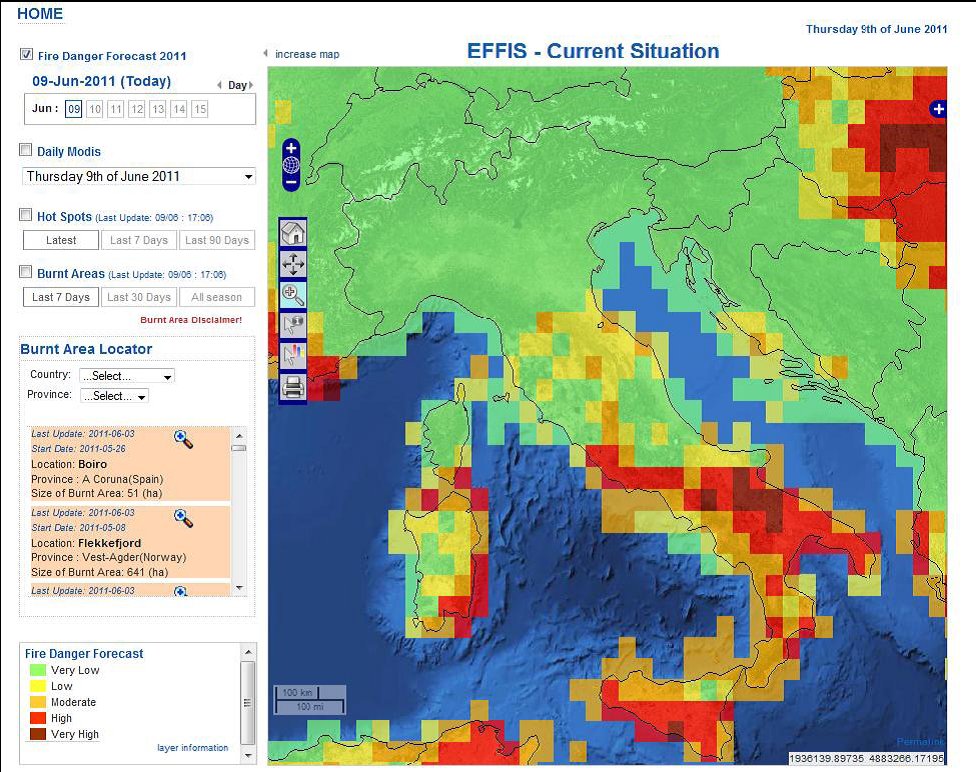
Example of portrayal of layer for the "typeOfHazard" flood: water depth and velocity (source: LAWA, 2010, Recommendations for the Establishment of Flood Hazard Maps and Flood Risk Maps. German Working Group on Water Issues of the Federal States and the Federal Government, Dresden) 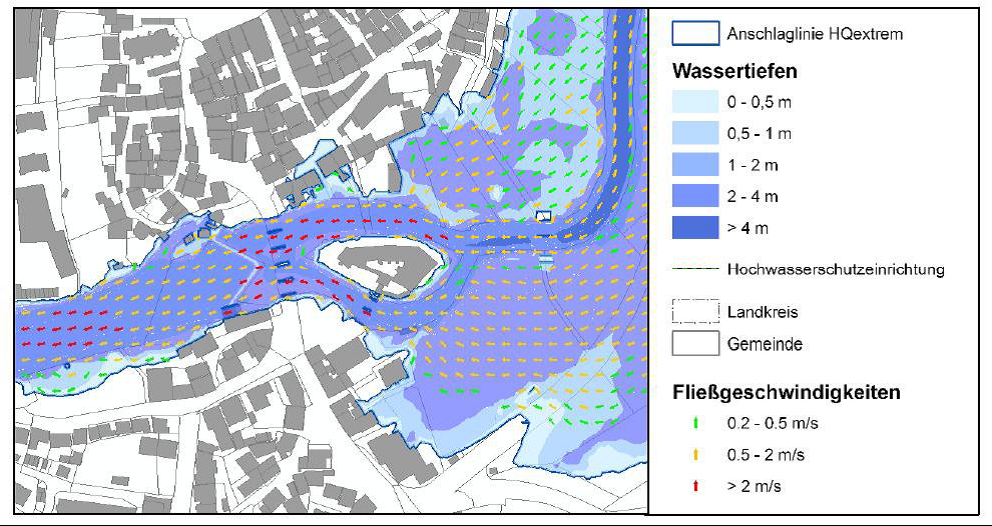
Example of portrayal of layer for the "typeOfHazard" landslide (source: Guzzetti, F. (2005) Landslide Hazard and Risk Assessment. PhD Thesis, Naturwissenschaftlichen Fakultät der Rheinischen Friedrich-Wilhelms-Universität, University of Bonn.http://geomorphology.irpi.cnr.it/Members/fausto/ph.d.-dissertation) 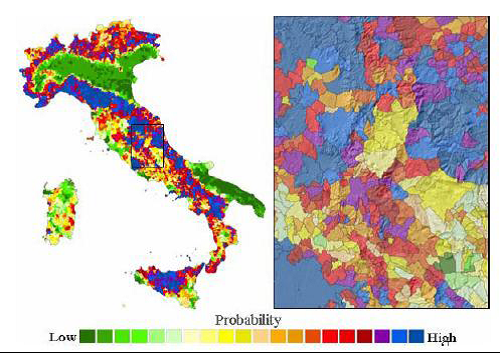
|
Symbology SLD |
The symbology is specified in the file: UserStyle_NZ_HazardArea.xml |
Minimum & maximum scales |
No scale limits |
11.2.4. Styles for the layer NZ.ObservedEvent - type of hazard
This style is for the representation of observed events as polygons or grid cells (coverage). Observed events are usually represented using a single colour schema depending on the values taken from the attribute "typeOfHazard". There are different portrayal schemas depending on hazard types. Therefore in this section we propose generic recommendations for the portrayal of observed events. The example in the table below shows a Styled Layer Descriptor (SLD) Symbology for observed floods.
| Style Name | NZ.ObservedEvent - type of hazard |
|---|---|
Style Title |
Observed Event |
Style Abstract |
This style is for the representation of observed events as polygons or grid cells (coverage). Observed events are usually represented using a single colour scheme depending on the "typeOfHazard". The example below shows a Styled Layer Descriptor (SLD) symbology for floods. |
Symbology SLD |
This example of symbology applies to floods feature Observed Event according to the scheme in Figure 10. The symbology is specified in the file: UserStyle_NZ_ObservedEvent.xml |
Minimum & maximum scales |
No scale limits |
11.2.5. Styles for the layer NZ.ExposedElement
| Style Name | NZ.ExposedElement |
|---|---|
Style Title |
Exposed element |
Style Abstract |
This style is for the representation of exposed elements data as points, lines, polygons or grid cells (coverage). Exposed elements are usually represented using a single colour coding. The example of exposed buildings in the figure of LAWA (2010: Recommendations for the Establishment of Flood Hazard Maps and Flood Risk Maps. German Working Group on Water Issues of the Federal States and the Federal Government, Dresden) shows buildings exposed to floods in grey fill and bold blue contour line. Buildings not exposed follow the same filling without the bold contour line. |
Symbology SLD |
The symbology is specified in the file: UserStyle_NZ_ExposedElement.xml |
Minimum & maximum scales |
No scale limits |
Bibliography
[DS-D2.3] INSPIRE DS-D2.3, Definition of Annex Themes and Scope, v3.0, https://knowledge-base.inspire.ec.europa.eu/publications/definition-annex-themes-and-scope-d-23-version-30_en
[DS-D2.5] INSPIRE DS-D2.5, Generic Conceptual Model, v3.4rc2, https://knowledge-base.inspire.ec.europa.eu/publications/inspire-generic-conceptual-model_en
[DS-D2.6] INSPIRE DS-D2.6, Methodology for the development of data specifications, v3.0, https://knowledge-base.inspire.ec.europa.eu/publications/methodology-development-data-specifications-baseline-version-d-26-version-30_en
[DS-D2.7] INSPIRE DS-D2.7, Guidelines for the encoding of spatial data, v3.3rc2, https://knowledge-base.inspire.ec.europa.eu/publications/guidelines-encoding-spatial-data_en
[ISO 19101] EN ISO 19101:2005 Geographic information – Reference model (ISO 19101:2002)
[ISO 19103] ISO/TS 19103:2005, Geographic information – Conceptual schema language
[ISO 19107] EN ISO 19107:2005, Geographic information – Spatial schema (ISO 19107:2003)
[ISO 19108] EN ISO 19108:2005 Geographic information - Temporal schema (ISO 19108:2002)
[ISO 19111] EN ISO 19111:2007 Geographic information - Spatial referencing by coordinates (ISO 19111:2007)
[ISO 19115] EN ISO 19115:2005, Geographic information – Metadata (ISO 19115:2003)
[ISO 19118] EN ISO 19118:2006, Geographic information – Encoding (ISO 19118:2005)
[ISO 19135] EN ISO 19135:2007 Geographic information – Procedures for item registration (ISO 19135:2005)
[ISO 19139] ISO/TS 19139:2007, Geographic information – Metadata – XML schema implementation
[ISO 19157] ISO/DIS 19157, Geographic information – Data quality
[OGC 06-103r3] Implementation Specification for Geographic Information - Simple feature access – Part 1: Common Architecture v1.2.0
Annex A: Abstract Test Suite - (normative)
Disclaimer |
The objective of the Abstract Test Suite (ATS) included in this Annex is to help the conformance testing process. It includes a set of tests to be applied on a data set to evaluate whether it fulfils the requirements included in this data specification and the corresponding parts of Commission Regulation No 1089/2010 (implementing rule as regards interoperability of spatial datasets and services, further referred to as ISDSS Regulation). This is to help data providers in declaring the conformity of a data set to the "degree of conformity, with implementing rules adopted under Article 7(1) of Directive 2007/2/EC", which is required to be provided in the data set metadata according to Commission Regulation (EC) No 2008/1205 (the Metadata Regulation).
Part 1 of this ATS includes tests that provide input for assessing conformity with the ISDSS regulation. In order to make visible which requirements are addressed by a specific test, references to the corresponding articles of the legal act are given. The way how the cited requirements apply to nz specification is described under the testing method.
In addition to the requirements included in ISDSS Regulation this Technical guideline contains TG requirements too. TG requirements are technical provisions that need to be fulfilled in order to be conformant with the corresponding IR requirement when the specific technical implementation proposed in this document is used. Such requirements relate for example to the default encoding described in section 9. Part 2 of the ATS presents tests necessary for assessing the conformity with TG requirements.
NOTE Conformance of a data set with the TG requirement(s) included in this ATS implies conformance with the corresponding IR requirement(s).
The ATS is applicable to the data sets that have been transformed to be made available through INSPIRE download services (i.e. the data returned as a response to the mandatory "Get Spatial Dataset" operation) rather than the original "source" data sets.
The requirements to be tested are grouped in several conformance classes. Each of these classes covers a specific aspect: one conformance class contains tests reflecting the requirements on the application schema, another on the reference systems, etc. Each conformance class is identified by a URI (uniform resource identifier) according to the following pattern:
http://inspire.ec.europa.eu/conformance-class/ir/nz/<conformance class identifier>
EXAMPLE 1 The URI http://inspire.ec.europa.eu/conformance-class/ir/ef/rs identifies the Reference Systems ISDSS conformance class of the Environmental Monitoring Facilities (EF) data theme.
The results of the tests should be published referring to the relevant conformance class (using its URI).
When an INSPIRE data specification contains more than one application schema, the requirements tested in a conformance class may differ depending on the application schema used as a target for the transformation of the data set. This will always be the case for the application schema conformance class. However, also other conformance classes could have different requirements for different application schemas. In such cases, a separate conformance class is defined for each application schema, and they are distinguished by specific URIs according to the following pattern:
http://inspire.ec.europa.eu/conformance-class/ir/nz/<conformance class identifier>/
<application schema namespace prefix>
EXAMPLE 2 The URI http://inspire.ec.europa.eu/conformance-class/ir/el/as/el-vec identifies the conformity with the application schema (as) conformance class for the Elevation Vector Elements (el-vec) application schema.
An overview of the conformance classes and the associated tests is given in the table below.
Table 6. Overview of the tests within this Abstract Test Suite.
A.1 Application Schema Conformance Class |
|||||||||
|
|||||||||
A.2 Reference Systems Conformance Class |
|||||||||
|
|||||||||
A.3 Data Consistency Conformance Class |
|||||||||
|
|||||||||
A.4 Metadata IR Conformance Class |
|||||||||
|
|||||||||
A.5 Information Accessibility Conformance Class |
|||||||||
|
|||||||||
A.6 Data Delivery Conformance Class |
|||||||||
|
|||||||||
A.7 Portrayal Conformance Class |
|||||||||
|
|||||||||
A.8 Technical Guideline Conformance Class |
|||||||||
|
In order to be conformant to a conformance class, a data set has to pass all tests defined for that conformance class.
In order to be conformant with the ISDSS regulation the inspected data set needs to be conformant to all conformance classes in Part 1. The conformance class for overall conformity with the ISDSS regulation is identified by the URI http://inspire.ec.europa.eu/conformance-class/ir/nz/.
In order to be conformant with the Technical Guidelines, the dataset under inspection needs to be conformant to all conformance classes included both in Part 1 and 2. Chapter 8 describes in detail how to publish the result of testing regarding overall conformity and conformity with the conformance classes as metadata. The conformance class for overall conformity with the Technical Guidelines is identified by the URI http://inspire.ec.europa.eu/conformance-class/tg/nz/3.0.
It should be noted that data providers are not obliged to integrate / decompose the original structure of the source data sets when they deliver them for INSPIRE. It means that a conformant dataset can contain less or more spatial object / data types than specified in the ISDSS Regulation.
A dataset that contains less spatial object and/or data types can be regarded conformant when the corresponding types of the source datasets after the necessary transformations fulfil the requirements set out in the ISDSS Regulation.
A dataset that contain more spatial object and/or data types may be regarded as conformant when
-
all the spatial object / data types that have corresponding types in the source dataset after the necessary transformations fulfil the requirements set out in the ISDSS Regulation and
-
all additional elements of the source model (spatial object types, data types, attributes, constraints and code lists together with their values) do not conflict with any rule defined in the interoperability target specifications defined for any theme within INSPIRE.
Open issue 1: Even though the last condition can be derived from Art. 8(4) of the Directive, the ISDSS Regulation does not contain requirements concerning the above issue. Therefore, no specific tests have been included in this abstract suite for testing conformity of extended application schemas. Annex F of the Generic Conceptual Model (D2.5) provides an example how to extend INSPIRE application schemas in a compliant way.
The ATS contains a detailed list of abstract tests. It should be noted that some tests in the Application schema conformance class can be automated by utilising xml schema validation tools. It should be noted that failing such validation test does not necessary reflect non-compliance to the application schema; it may be the results of erroneous encoding.
Each test in this suite follows the same structure:
-
Requirement: citation from the legal texts (ISDSS requirements) or the Technical Guidelines (TG requirements);
-
Purpose: definition of the scope of the test;
-
Reference: link to any material that may be useful during the test;
-
Test method: description of the testing procedure.
According to ISO 19105:2000 all tests in this ATS are basic tests. Therefore, this statement is not repeated each time.
Part 1 - (normative)
Conformity with Commission Regulation No 1089/2010
A.1. Application Schema Conformance Class
Conformance class:
A.1.1. Schema element denomination test
-
Purpose: Verification whether each element of the dataset under inspection carries a name specified in the target application schema(s).
-
Reference: Art. 3 and Art.4 of Commission Regulation No 1089/2010
-
Test Method: Examine whether the corresponding elements of the source schema (spatial object types, data types, attributes, association roles and code lists) are mapped to the target schema with the correct designation of mnemonic names.
NOTE Further technical information is in the Feature catalogue and UML diagram of the application schema(s) in section 5.2.
A.1.2. Value type test
-
Purpose: Verification whether all attributes or association roles use the corresponding value types specified in the application schema(s).
-
Reference: Art. 3, Art.4, Art.6(1), Art.6(4), Art.6(5) and Art.9(1)of Commission Regulation No 1089/2010.
-
Test Method: Examine whether the value type of each provided attribute or association role adheres to the corresponding value type specified in the target specification.
NOTE 1 This test comprises testing the value types of INSPIRE identifiers, the value types of attributes and association roles that should be taken from code lists, and the coverage domains.
NOTE 2 Further technical information is in the Feature catalogue and UML diagram of the application schema(s) in section 5.2.
A.1.3. Value test
-
Purpose: Verify whether all attributes or association roles whose value type is a code list take the values set out therein.
-
Reference: Art.4 (3) of Commission Regulation No 1089/2010.
-
Test Method: When an attribute / association role has a code list as its type, compare the values of each instance with those provided in the application schema. To pass this tests any instance of an attribute / association role
-
shall take only a value explicitly specified in the code list or shall take a value that is narrower (i.e. more specific) than those explicitly specified in the application schema when the code list’s extensibility is "narrower".
-
NOTE 1 This test is not applicable to code lists with extensibility "open" or "any".
NOTE 2 When a data provider only uses code lists with narrower (more specific values) this test can be fully performed based on internal information.
NOTE 3 The code list ExposedElementCategoryValue is defined with the extensibility "open". Before using a new or more detailed term the definitions of all values of a relevant code list should be checked (see Recommendation 4)
A.1.4. Attributes/associations completeness test
-
Purpose: Verification whether each instance of spatial object type and data types include all attributes and association roles as defined in the target application schema.
-
Reference: Art. 3, Art.4(1), Art.4(2), and Art.5(2) of Commission Regulation No 1089/2010.
-
Test Method: Examine whether all attributes and association roles defined for a spatial object type or data type are present for each instance in the dataset.
NOTE 1 Further technical information is in the Feature catalogue and UML diagram of the application schema(s) in section 5.2.
NOTE 2 For all properties defined for a spatial object, a value has to be provided if it exists in or applies to the real world entity – either the corresponding value (if available in the data set maintained by the data provider) or the value of void. If the characteristic described by the attribute or association role does not exist in or apply to the real world entity, the attribute or association role does not need to be present in the data set.
A.1.5. Abstract spatial object test
-
Purpose: Verification whether the dataset does NOT contain abstract spatial object / data types defined in the target application schema(s).
-
Reference: Art.5(3) of Commission Regulation No 1089/2010
-
Test Method: Examine that there are NO instances of abstract spatial object / data types in the dataset provided.
NOTE Further technical information is in the Feature catalogue and UML diagram of the application schema(s) in section 5.2.
A.1.6. Constraints test
-
Purpose: Verification whether the instances of spatial object and/or data types provided in the dataset adhere to the constraints specified in the target application schema(s).
-
Reference: Art. 3, Art.4(1), and Art.4(2) of Commission Regulation No 1089/2010.
-
Test Method: Examine all instances of data for the constraints specified for the corresponding spatial object / data type. Each instance shall adhere to all constraints specified in the target application schema(s).
NOTE Further technical information is in the Feature catalogue and UML diagram of the application schema(s) in section 5.2.
A.1.7. Geometry representation test
-
Purpose: Verification whether the value domain of spatial properties is restricted as specified in the Commission Regulation No 1089/2010.
-
Reference: Art.12(1) of Commission Regulation No 1089/2010
-
Test Method: Check whether all spatial properties only use 0, 1 and 2-dimensional geometric objects that exist in the right 2-, 3- or 4-dimensional coordinate space, and where all curve interpolations respect the rules specified in the reference documents.
NOTE Further technical information is in OGC Simple Feature spatial schema v1.2.1 [06-103r4].
A.1.8. Risk zone – theme specific test 1
-
Purpose: Verification whether each Risk Zone and/or Risk Zone Coverage are spatially associated – overlap - with a spatial extent of a Hazard Area.
-
Reference: Annex IV. Section 12.6. (1) of Commission Regulation No 1089/2010
-
Test Method: Check whether all instances of the RiskZone and/or RiskZoneCoverage spatial object types overlap with an instance of the HazardArea spatial object type.
A.1.9. Risk zone – theme specific test 2
-
Purpose: Verification whether each Risk Zone and/or Risk Zone Coverage are spatially associated – overlap - with at least one Exposed Element.
-
Reference: Annex IV. Section 12.6. (2) of Commission Regulation No 1089/2010
-
Test Method: Check whether all instances of the RiskZone and/or RiskZoneCoverage spatial object types overlap with at least one instance of the ExposedElement spatial object type.
A.2. Reference Systems Conformance Class
Conformance class:
A.2.1. Datum test
-
Purpose: Verify whether each instance of a spatial object type is given with reference to one of the (geodetic) datums specified in the target specification.
-
Reference: Annex II Section 1.2 of Commission Regulation No 1089/2010
-
Test Method: Check whether each instance of a spatial object type specified in the application schema(s) in section 5 has been expressed using:
-
the European Terrestrial Reference System 1989 (ETRS89) within its geographical scope; or
-
the International Terrestrial Reference System (ITRS) for areas beyond the ETRS89 geographical scope; or
-
other geodetic coordinate reference systems compliant with the ITRS. Compliant with the ITRS means that the system definition is based on the definition of ITRS and there is a well-established and described relationship between both systems, according to the EN ISO 19111.
-
NOTE Further technical information is given in Section 6 of this document.
A.2.2. Coordinate reference system test
-
Purpose: Verify whether the two- and three-dimensional coordinate reference systems are used as defined in section 6.
-
Reference: Section 6 of Commission Regulation 1089/2010.
-
Test Method: Inspect whether the horizontal and vertical components of coordinates one of the corresponding coordinate reference system has been:
-
Three-dimensional Cartesian coordinates based on a datum specified in 1.2 and using the parameters of the Geodetic Reference System 1980 (GRS80) ellipsoid.
-
Three-dimensional geodetic coordinates (latitude, longitude and ellipsoidal height) based on a datum specified in 1.2 and using the parameters of the GRS80 ellipsoid.
-
Two-dimensional geodetic coordinates (latitude and longitude) based on a datum specified in 1.2 and using the parameters of the GRS80 ellipsoid.
-
Plane coordinates using the ETRS89 Lambert Azimuthal Equal Area coordinate reference system.
-
Plane coordinates using the ETRS89 Lambert Conformal Conic coordinate reference system.
-
Plane coordinates using the ETRS89 Transverse Mercator coordinate reference system.
-
For the vertical component on land, the European Vertical Reference System (EVRS) shall be used to express gravity-related heights within its geographical scope. Other vertical reference systems related to the Earth gravity field shall be used to express gravity-related heights in areas that are outside the geographical scope of EVRS.
-
For the vertical component in marine areas where there is an appreciable tidal range (tidal waters), the Lowest Astronomical Tide (LAT) shall be used as the reference surface.
-
For the vertical component in marine areas without an appreciable tidal range, in open oceans and effectively in waters that are deeper than 200 meters, the Mean Sea Level (MSL) or a well-defined reference level close to the MSL shall be used as the reference surface."
-
For the vertical component in the free atmosphere, barometric pressure, converted to height using ISO 2533:1975 International Standard Atmosphere, or other linear or parametric reference systems shall be used. Where other parametric reference systems are used, these shall be described in an accessible reference using EN ISO 19111-2:2012.
-
NOTE Further technical information is given in Section 6 of this document.
A.2.3. Grid test
-
Purpose: Verify that gridded data related are available using the grid compatible with one of the coordinate reference systems defined in Commission Regulation No 1089/2010
-
Reference: Annex II Section 2.1 and 2.2 of Commission Regulation 1089/2010.
-
Test Method: Check whether the dataset defined as a grid is compatible with one of the coordinate reference.
-
Grid_ETRS89_GRS80 based on two-dimensional geodetic coordinates using the parameters of the GRS80 ellipsoid
-
Grid_ETRS89_GRS80zn based on two-dimensional geodetic coordinates with zoning,
-
Plane coordinates using the Lambert Azimuthal Equal Area projection and the parameters of the GRS80 ellipsoid (ETRS89-LAEA)
-
Plane coordinates using the Lambert Conformal Conic projection and the parameters of the GRS80 ellipsoid (ETRS89-LCC)
-
Plane coordinates using the Transverse Mercator projection and the parameters of the GRS80 ellipsoid (ETRS89-TMzn)
-
NOTE Further technical information is given in Section 6 of this document.
NOTE 2 This test applies to Hazard Areas, Risk Zones, Exposed Elements and Observed Events spatial object types presented as coverages
A.2.4. View service coordinate reference system test
-
Purpose: Verify whether the spatial data set is available in the two dimensional geodetic coordinate system for their display with the INSPIRE View Service.
-
Reference: Annex II Section 1.4 of Commission Regulation 1089/2010
-
Test Method: Check that each instance of a spatial object types specified in the application schema(s) in section 5 is available in the two-dimensional geodetic coordinate system
NOTE Further technical information is given in Section 6 of this document.
A.2.5. Temporal reference system test
-
Purpose: Verify whether date and time values are given as specified in Commission Regulation No 1089/2010.
-
Reference: Art.11(1) of Commission Regulation 1089/2010
-
Test Method: Check whether:
-
the Gregorian calendar is used as a reference system for date values;
-
the Universal Time Coordinated (UTC) or the local time including the time zone as an offset from UTC are used as a reference system for time values.
-
NOTE Further technical information is given in Section 6 of this document.
A.2.6. Units of measurements test
-
Purpose: Verify whether all measurements are expressed as specified in Commission Regulation No 1089/2010.
-
Reference: Art.12(2) of Commission Regulation 1089/2010
-
Test Method: Check whether all measurements are expressed in SI units or non-SI units accepted for use with the International System of Units.
NOTE 1 Further technical information is given in ISO 80000-1:2009.
NOTE 2 Degrees, minutes and seconds are non-SI units accepted for use with the International System of Units for expressing measurements of angles.
A.3. Data Consistency Conformance Class
Conformance class:
A.3.1. Unique identifier persistency test
-
Purpose: Verify whether the namespace and localId attributes of the external object identifier remain the same for different versions of a spatial object.
-
Reference: Art. 9 of Commission Regulation 1089/2010.
-
Test Method: Compare the namespace and localId attributes of the external object identifiers in the previous version(s) of the dataset with the namespace and localId attributes of the external object identifiers of current version for the same instances of spatial object / data types; To pass the test, neither the namespace, nor the localId shall be changed during the life-cycle of a spatial object.
NOTE 1 This test can be performed exclusively on the basis of the information available in the database of the data providers.
NOTE 2 When using URI this test includes the verification whether no part of the construct has been changed during the life cycle of the instances of spatial object / data types.
NOTE 3 Further technical information is given in section 14.2 of the INSPIRE Generic Conceptual Model.
A.3.2. Version consistency test
-
Purpose: Verify whether different versions of the same spatial object / data type instance belong to the same type.
-
Reference: Art. 9 of Commission Regulation 1089/2010.
-
Test Method: Compare the types of different versions for each instance of spatial object / data type
NOTE 1 This test can be performed exclusively on the basis of the information available in the database of the data providers.
A.3.3. Life cycle time sequence test
-
Purpose: Verification whether the value of the attribute beginLifespanVersion refers to an earlier moment of time than the value of the attribute endLifespanVersion for every spatial object / object type where this property is specified.
-
Reference: Art.10(3) of Commission Regulation 1089/2010.
-
Test Method: Compare the value of the attribute beginLifespanVersion with attribute endLifespanVersion. The test is passed when the beginLifespanVersion value is before endLifespanVersion value for each instance of all spatial object/data types for which this attribute has been defined.
NOTE 1 This test can be performed exclusively on the basis of the information available in the database of the data providers.
A.3.4. Validity time sequence test
-
Purpose: Verification whether the value of the attribute validFrom refers to an earlier moment of time than the value of the attribute validTo for every spatial object / object type where this property is specified.
-
Reference: Art.12(3) of Commission Regulation 1089/2010.
-
Test Method: Compare the value of the attribute validFrom with attribute validTo. The test is passed when the validFrom value is before validTo value for each instance of all spatial object/data types for which this attribute has been defined.
NOTE 1 This test can be performed exclusively on the basis of the information available in the database of the data providers.
A.3.5. Update frequency test
-
Purpose: Verify whether all the updates in the source dataset(s) have been transmitted to the dataset(s) which can be retrieved for the NZ data theme using INSPIRE download services.
-
Reference: Art.8 (2) of Commission Regulation 1089/2010.
-
Test Method: Compare the values of beginning of life cycle information in the source and the target datasets for each instance of corresponding spatial object / object types. The test is passed when the difference between the corresponding values is less than 6 months.
NOTE 1 This test can be performed exclusively on the basis of the information available in the database of the data providers.
A.4. Metadata IR Conformance Class
Conformance class:
A.4.1. Metadata for interoperability test
-
Purpose: Verify whether the metadata for interoperability of spatial data sets and services described in 1089/2010 Commission Regulation have been created and published for each dataset related to the NZ data theme.
-
Reference: Art.13 of Commission Regulation 1089/2010
-
Test Method: Inspect whether metadata describing the coordinate reference systems, encoding, and spatial representation type have been created and published. If the spatial data set contains temporal information that does not refer to the default temporal reference system, inspect whether metadata describing the temporal reference system have been created and published. If an encoding is used that is not based on UTF-8, inspect whether metadata describing the character encoding have been created.
NOTE Further technical information is given in section 8 of this document.
A.5. Information Accessibility Conformance Class
Conformance class:
A.5.1. Code list publication test
-
Purpose: Verify whether all additional values used in the data sets for attributes, for which narrower values or any other value than specified in Commission Regulation 1089/2010 are allowed, are published in a register.
-
Reference: Art.6(3) and Annex IV Section 12.5
-
Test Method: For each additional value used in the data sets for code list-valued attributes, check whether it is published in a register.
NOTE Further technical information is given in section 5 of this document.
A.5.2. CRS publication test
-
Purpose: Verify whether the identifiers and the parameters of coordinate reference system are published in common registers.
-
Reference: Annex II Section 1.5
-
Test Method: Check whether the identifier and the parameter of the CRS used for the dataset are included in a register. .
NOTE Further technical information is given in section 6 of this document.
A.5.3. CRS identification test
-
Purpose: Verify whether identifiers for other coordinate reference systems than specified in Commission Regulation 1089/2010 have been created and their parameters have been described according to EN ISO 19111 and ISO 19127.
-
Reference: Annex II Section 1.3.4
-
Test Method: Check whether the register with the identifiers of the coordinate reference systems is accessible.
NOTE Further technical information is given in section 6 of this document.
A.5.4. Grid identification test
-
Purpose: Verify whether identifiers for other geographic grid systems than specified in Commission Regulation 1089/2010 have been created and their definitions have been either described with the data or referenced.
-
Reference: Annex II Section 2.1 and 2.2
-
Test Method: Check whether the identifiers for grids have been created. Inspect the dataset and/or the metadata for inclusion of grid definition.
NOTE Further technical information is given in section 6 of this document.
A.6. Data Delivery Conformance Class
Conformance class:
A.6.1. Encoding compliance test
-
Purpose: Verify whether the encoding used to deliver the dataset comply with EN ISO 19118.
-
Reference: Art.7 (1) of Commission Regulation 1089/2010.
-
Test Method: Follow the steps of the Abstract Test Suit provided in EN ISO 19118.
NOTE 1 Datasets using the default encoding specified in Section 9 fulfil this requirement.
NOTE 2 Further technical information is given in Section 9 of this document.
A.7. Portrayal Conformance Class
Conformance class:
A.7.1. Layer designation test
-
Purpose: verify whether each spatial object type has been assigned to the layer designated according to Commission Regulation 1089/2010.
-
Reference: Art. 14(1), Art14(2) and Annex IV Section 12.7.
-
Test Method: Check whether data is made available for the view network service using the specified layers respectively:
Layer Name |
NZ.RiskZone |
NZ.RiskZoneCoverage |
NZ.ExposedElement |
NZ.ExposedElementCoverage |
NOTE Further technical information is given in section 11 of this document.
Part 2 - (informative)
Conformity with the technical guideline (TG) Requirements
A.8. Technical Guideline Conformance Class
Conformance class:
A.8.1. Multiplicity test
-
Purpose: Verify whether each instance of an attribute or association role specified in the application schema(s) does not include fewer or more occurrences than specified in section 5.
-
Reference: Feature catalogue and UML diagram of the application schema(s) in section 5 of this guideline.
-
Test Method: Examine that the number of occurrences of each attribute and/or association role for each instance of a spatial object type or data type provided in the dataset corresponds to the number of occurrences of the attribute / association role that is specified in the application schema(s) in section 5.
A.8.2. CRS http URI test
-
Purpose: Verify whether the coordinate reference system used to deliver data for INSPIRE network services has been identified by URIs according to the EPSG register.
-
Reference: Section 6 of this technical guideline
-
Test Method: Compare the URI of the dataset with the URIs in the table.
NOTE 1 Passing this test implies the fulfilment of test A6.2
NOTE 2 Further reference please see http://www.epsg.org/geodetic.html
A.8.3. Metadata encoding schema validation test
-
Purpose: Verify whether the metadata follows an XML schema specified in ISO/TS 19139.
-
Reference: Section 8 of this technical guideline, ISO/TS 19139
-
Test Method: Inspect whether provided XML schema is conformant to the encoding specified in ISO 19139 for each metadata instance.
NOTE 1 Section 2.1.2 of the Metadata Technical Guidelines discusses the different ISO 19139 XML schemas that are currently available.
A.8.4. Metadata occurrence test
-
Purpose: Verify whether the occurrence of each metadata element corresponds to those specified in section 8.
-
Reference: Section 8 of this technical guideline
-
Test Method: Examine the number of occurrences for each metadata element. The number of occurrences shall be compared with its occurrence specified in Section 8:
NOTE 1 Section 2.1.2 of the Metadata Technical Guidelines discusses the different ISO 19139 XML schema
A.8.5. Metadata consistency test
-
Purpose: Verify whether the metadata elements follow the path specified in ISO/TS 19139.
-
Reference: Section 8 of this technical guideline, ISO/TS 19139
-
Test Method: Compare the XML schema of each metadata element with the path provide in ISO/TS 19137.
NOTE 1 This test does not apply to the metadata elements that are not included in ISO/TS 19139.
A.8.6. Encoding schema validation test
-
Purpose: Verify whether the provided dataset follows the rules of default encoding specified in section 9 of this document
-
Reference: section 9 of this technical guideline
-
Test Method: Inspect whether provided encoding(s) is conformant to the encoding(s) for the relevant application schema(s) as defined in section 9:
NOTE 1 Applying this test to the default encoding schema described in section 9 facilitates testing conformity with the application schema specified in section 5. In such cases running this test with positive result may replace tests from A1.1 to A1.4 provided in this abstract test suite.
NOTE 2 Using Schematron or other schema validation tool may significantly improve the validation process, because some some complex constraints of the schema cannot be validated using the simple XSD validation process. On the contrary to XSDs Schematron rules are not delivered together with the INSPIRE data specifications. Automating the process of validation (e.g. creation of Schematron rules) is therefore a task and an opportunity for data providers.
A.8.7. Coverage multipart representation test
-
Purpose: Verify whether coverage data encoded as multipart messages comply with the multipart representation conformance class defined in GML Application Schema for Coverages [OGC 09-146r2].
-
Reference: OGC standard GML Application Schema for Coverages [OGC 09-146r2].
-
Test Method: Inspect whether coverage data encoded as multipart messages comply with the multipart representation conformance class defined in GML Application Schema for Coverages [OGC 09-146r2].
NOTE further information is provided in section 9.4 of this technical guideline.
NOTE 2 This test applies to Hazard Areas, Risk Zones, Exposed Elements and Observed Events spatial object types presented as coverages
A.8.8. Coverage domain consistency test
-
Purpose: Verify whether the encoded coverage domain is consistent with the information provided in the GML application schema.
-
Reference: Section 9.4.1.2 of this technical guideline.
-
Test Method: For multipart coverage messages compare the encoded coverage domain with the description of the coverage component in the GML application schema
NOTE 1 This test applies only to those multipart messages, where the coverage range is encoded together with the coverage domain (some binary formats).
NOTE 2 .This test does not apply to multipart messages where the coverage range is embedded without describing the data structure (e.g. text based formats).
A.8.9. Style test
-
Purpose: Verify whether the styles defined in section 11.2 have been made available for each specified layer.
-
Reference: section 11.2.
-
Test Method: Check whether the styles defined in section 11.2 have been made available for each specified layer.
Annex B: Use cases - (informative)
This annex describes the use cases that were used as a basis for the development of this data specification.
Table of use cases:
B.1 |
Calculation of Flood impact |
B.2 |
Reporting - Flood Risk Maps for 2007/60/EC |
B.3 |
Risk Management scenario in France |
B.4 |
Forest Fires |
B.4.1 |
Forest fires danger mapping |
B.4.2 |
Forest fire vulnerability mapping |
B.4.3 |
Forest fire risk mapping |
B.5 |
Landslides |
B.5.1 |
Landslide hazard mapping |
B.5.2 |
Landslide vulnerability assessment |
B.5.3 |
Landslide Risk assessment |
B.6 |
Earthquake insurance |
B.1. Calculation of Flood impact
| Use Case Description | |
|---|---|
Name |
Calculation of Flood impact |
Primary actor |
Analyst |
Goal |
Assessing of the presumed impact of a specific flood |
System under |
Flood Information System |
Importance |
medium - high |
Description |
The analyst calculates for a given flood extent a set of maps that shows the affected area, number of people and type of land use that are affected by administrative unit (NUTS3) |
Pre-condition |
Flood extent has been calculated (if the analysis is based on a simulated event) or delineated on basis of orthophotos (if extent is based on a past event) |
Post-condition |
Flood impact dataset |
Flow of Events – Basic Path |
|
Step 1. |
The analyst imports the flood extent |
Step 2. |
The analyst identifies the administrative units (NUTS3) affected by the flood |
Step 3. |
For each administrative unit the analyst calculates the area that the flood extent covers (in ha) |
Step 4. |
For each administrative unit the analyst calculates the number of people living in the flooded area, based on a population density map |
Step 5. |
For each administrative unit the analyst calculates the affected land cover type (in ha) based on land cover information |
Step 6. |
The analyst combines all three thematic layers in a single flood impact dataset |
Flow of Events – Alternative Paths |
|
NONE |
|
Data set: Flood extent |
|
Description |
Flood extent showing the total extent of the flood |
Type |
input |
Data provider |
Flood monitoring centre |
Geographic scope |
Country XYZ |
Thematic scope |
Flood extent. Either based on historic observation or on flood simulation. |
Scale, resolution |
1:25.000 |
Delivery |
Online |
Documentation |
|
Data set: NUTS3 |
|
Description |
Administrative boundaries |
Type |
input |
Data provider |
EUROSTAT |
Geographic scope |
European |
Thematic scope |
Administrative boundaries |
Scale, resolution |
1:250.000 |
Delivery |
Online |
Documentation |
|
Data set: Population density map |
|
Description |
Population density map |
Type |
input |
Data provider |
Country’s statistical office |
Geographic scope |
Country XYZ |
Thematic scope |
Population density per grid cell for a 250 x 250 m grid |
Scale, resolution |
250m |
Delivery |
DVD |
Documentation |
|
Data set: CORINE Land Cover |
|
Description |
Corine Land Cover 2006 raster data – version 13 (02/2010) |
Type |
input |
Data provider |
EEA |
Geographic scope |
Country XYZ |
Thematic scope |
Raster data on land cover for the CLC2006 inventory |
Scale, resolution |
250m |
Delivery |
online |
Documentation |
http://www.eea.europa.eu/data-and-maps/data/corine-land-cover-2006-raster |
Data set: Flood impact |
|
Description |
The output of the flood impact analysis |
Type |
output |
Data provider |
The analysts organisation |
Geographic scope |
Country XYZ |
Thematic scope |
Flood impact indicator (scale 1-5) by NUTS3 administrative unit |
Scale, resolution |
1:250.000 |
Delivery |
online |
Documentation |
|
Use case "Calculation of Floods Impact" describes how an analyst could carry out the level of flood impacts for human population at overview scale (at Country or at European wide level). This example shows that even when flood extents are available on local or regional level the meaningful output scale (here: flood impact dataset = 1:250.000) depends on the lowest scale of input datasets.
B.2. Reporting - Flood Risk Maps for 2007/60/EC
| Use Case Description | |
|---|---|
Name |
Production of Flood Risk Maps |
Primary actor |
Analyst |
Goal |
Informing about potential adverse consequences (= impacts) for specific "exposed elements" for each area with potential significant flood risk |
System under |
GIS |
Importance |
high |
Description |
The analyst prepares for given flood extents maps that show potential affected areas and potential adverse consequences - expressed in terms of the indicative number of inhabitants, the type of economic activities, location of installations which might cause accidental pollution in the case of flooding and potentially affected protected areas (according to WFD Annex IV (1) (i) (iii) and (v)) under different flood scenarios. The flood maps must be prepared for the following flooding scenarios: floods with low probability, or extreme event scenarios; flood with a medium probability (likely return period ≥ 100 years); floods with a high probability, where appropriate. Remark: cf. Reporting Sheet "Flood Hazard and Risk Maps". |
Pre-condition |
Calculated flood extents for each applicable type of flood and for each of the different scenarios. Flood extents are usually carried out by modelling. Preprocessed datasets about "exposed elements". Remark: Process of coordination in shared River Basins Districts and/or Units of Management for flow of events and data sets assumed. |
Post-condition |
Datasets with potential adverse consequences for different types of flood under different scenarios |
Flow of Events – Basic Path |
|
Step 1. |
The analyst imports the areas with potential significant flood risk and flood extent datasets for the different types of flood and different scenarios (flood defence infrastructure is already considered in case of flood extent for floods with high and medium probability, no consideration of flood defence infrastructure for floods with low probability). |
Step 2. |
The analyst imports datasets with information about indicative number of inhabitants, types of economic activities, locations of installations which might cause accidental pollution in the case of flooding and potentially affected protected areas |
Step 3. |
For each area with potential significant flood risk the analyst identifies the indicative number of inhabitants, the type of economic activities, location of installations which might cause accidental pollution in the case of flooding and potentially affected protected areas (according to WFD Annex IV (1) (i) (iii) and (v) under different flood scenarios. |
Step 4. |
The analyst decides about map contents, the number of maps to be provided for each area with potential significant flood risk and in this context about the most appropriate map scale and the adequate way to provide information carried out by step 3 and 5. In dependence of scale and assessed adverse consequences for the different types of flood and scenarios it is feasible to provide more than one map respectively separate maps for the same area. For groundwater flooding and coastal floods where an adequate level of protection is in place the analyst decides to prepare flood risk maps for all scenarios or to limit scenarios to low probability or extreme event scenario. |
Step 5. |
Grouping/combining of thematic layers for map/separate maps |
Step 6. |
Reporting to WISE (Water Information System for Europe) |
Flow of Events – Alternative Paths |
|
Step 1. |
The analyst imports the areas with potential significant flood risk and flood extent datasets for the different types of flood and different scenarios |
Step 2. |
The analyst imports datasets with information about indicative number of inhabitants, types of economic activities, locations of installations which might cause accidental pollution in the case of flooding and potentially affected protected areas |
Step 3. |
For each area with potential significant flood risk the analyst identifies the indicative number of inhabitants, the type of economic activities, location of installations which might cause accidental pollution in the case of flooding and potentially affected protected areas (according to WFD Annex IV (1) (i) (iii) and (v) under different flood scenarios. |
Step 4. |
The analyst imports datasets with flood defence infrastructure |
Step 5. |
For each area with potential significant flood risk the analyst identifies where an adequate level of protection is in place |
Step 6. |
For groundwater flooding and coastal floods where an adequate level of protection is in place the analyst decides to prepare flood risk maps for all scenarios or to limit scenarios to low probability or extreme event scenario. |
Step 7. |
The analyst decides about map contents, the number of maps to be provided for each area with potential significant flood risk and in this context about the most appropriate map scale and the adequate way to provide information carried out by step 3 and 5. In dependence of scale and assessed adverse consequences for the different types of flood and scenarios it is feasible to provide more than one map respectively separate maps for the same area. |
Step 8. |
Grouping/combining of thematic layers for map/separate maps |
Step 9. |
Reporting to WISE (Water Information System for Europe) |
Data set: Flood Extent |
|
Description |
Flood extent for different types of flood and for each type of flood for different scenarios |
Type |
input |
Data provider |
Analyst of competent authority |
Geographic scope |
Country/State |
Thematic scope |
Flood extent (usually basing on documented extents of past flood events and flood modelling for different scenarios) |
Scale, resolution |
1: 2.500 – 1:25.000 |
Delivery |
WFS |
Documentation |
|
Data set: Population |
|
Description |
Population on municipality level (number of inhabitants in each municipality) |
Type |
input |
Data provider |
Statistical office on country/state level |
Geographic scope |
Country/State |
Thematic scope |
Population per municipality |
Scale, resolution |
1: 2.500 – 1:25.000 |
Delivery |
EXCEL-Table with number of inhabitants for each municipality |
Documentation |
|
Data set: Land Use |
|
Description |
Land Use |
Type |
input |
Data provider |
Map Agency on country/state level |
Geographic scope |
Country/State |
Thematic scope |
Vector data on land use, to be pre-processed for "economic activities" by aggregating/classifying |
Scale, resolution |
1: 2.000 – 1:25.000 |
Delivery |
Fixed hard disk |
Documentation |
|
Data set: Industrial plants (as an example for "locations of installations") |
|
Description |
plants falling under 2010/70/EC on industrial emissions (formerly 2008/1/EC respectively Directive 96/61/EC Annex I, known as IPPC Directive, concerning integrated pollution prevention and control) |
Type |
input |
Data provider |
State Agency |
Geographic scope |
Country/State |
Thematic scope |
Vector data |
Scale, resolution |
1: 2.500 – 1:25.000 |
Delivery |
GIS-file |
Documentation |
|
Data set: Protected Sites - Habitats (as an example for protected areas ) |
|
Description |
Protected sites falling under Habitats Directive |
Type |
input |
Data provider |
Agency for protection of the Environment |
Geographic scope |
Country/State |
Thematic scope |
Vector data |
Scale, resolution |
1: 5.000 – 1:25.000 |
Delivery |
Online |
Documentation |
|
Use Case "Reporting – Flood Risk Maps for 2007/60/EC" describes using examples, how steps for preparation of flood risk maps could look like in Member States. Therefore this example has no binding character (reporting requirements are layed down in Floods Directive Reporting Sheets and documents like Floods Directive GIS Guidance, which is in progress). The mentioned examples for input data sets point out existing linkages to other INSPIRE-relevant themes (for example Annex I theme Protected Sites, Annex III theme Production and Industrial Facilities).
Please note that domain specific terms of 2007/60/EC (flood directive) and of Data Specification Natural Risk Zones are not necessarily identical because TWG NZ has to cover many categories of hazards and respectively risks.
To illustrate how the terms/contents that are used in Floods Directive (2007/60/EC) are addressed in the core feature types model for NZ or related with other INSPIRE themes TWG NZ provides following overview.
| FD terminology | NZ terminology | Other Inspire theme(s) / TWG(s) |
|---|---|---|
UoM – Unit of Management Units of management may be individual river basins and/or certain coastal areas, and may be entirely within national borders or may be part of an international unit of management or international river basin district. |
- |
Area management, Hydrography |
Flood Location Location of past significant floods or where potential future significant floods could occur, could be a town or other area that was flooded, or stretches of rivers /coastal areas |
HazardArea and/orRiskZone |
Hydrography, Administrative Units etc. |
SpecificArea locality, river basin, sub-basin and/or coastal area or other areas associated with article 4 |
- |
Hydrography, Administrative Units, Area Management |
AreasOfFloodRisk Areas with potential significant flood risk (APSFR), can be indicated as entire or stretches of river/coastal areas, areas, polygons, entire river basins. |
HazardArea and/orRiskZone |
Hydrography |
TypeOfFlood |
SpecificRiskOrHazardType |
|
TypeOfPotentialConsequences |
TypeOfExposedElements |
Production and Industrial Facilities, Protected Sites, Hydrography, Land Use, Human Health and Safety, Transport Networks, Buildings etc |
Recurrence |
LikelihoodOfOccurence |
|
Frequency |
LikelihoodOfOccurence |
|
Fatalities |
LevelOfHazard |
|
Degree_TotalDamageHumanHealth |
LevelOfHazard |
|
Degree_TotalDamageXYZ |
LevelOfHazard |
B.3. Risk Management scenario in France
Figure 1: Actors for risk management in France
Narrative description
This case is provided as an example to contribute to the understanding of the hazard and risk area definition process.
In France, the Ministry of Environment is in charge of making the natural risks analysis (including hazard area definition). Usually, a natural risk zone analysis for a certain type of natural hazard over a certain territory is done at most once every 10 years.
The central level defines the methodology as well as the territories for which risk analysis must be made. Then, the risk analysis itself is made in each region, still by the Ministry.
Once the risk analysis is done, the Ministry of Environment makes their official release.
The vulnerability calculation is seldom carried out by the Ministry of Equipment. When it is done, it is done most of the time at a low-scale level. The risk modeler calculates the vulnerability of a territory (a city, or a block) to a specific hazard. For some very high-risk areas (such as the earthquake risk over the city of Grenoble, or earthquake / volcano risks in the West Indies), the Ministry triggers a high-precision vulnerability assessment of infrastructure and buildings. In this case, the assessment of the vulnerability is done by an expert (with architectural background), after a field investigation.
Once released, risk zones and hazard areas can then be used and analyzed at a local level. Local planners will then use those risk zones to define their policies for risk mitigation and disaster management. It is these risks that have a legal basis.
Due to the fact that local planners may have more accurate and / or more up-to-date data (if hazard areas may not change in 10 years -the natural environment and the methodology do not change that often-, the exposed elements, that are a representation of human activities evolve much faster), they overlay the risk zones and hazard areas with topographical databases that might be other than those used by the central level of Ministry of Equipment.
The local planners finally calculate the vulnerability of what they consider as exposed elements to the natural hazard that is considered.
Local planners may also link those risks zones into their land-use management plans. They also may plan to set natural hazards monitoring facilities.
Detailed and structured description
-
Color code for detailed description:
-
Hazard modeler
-
Topographical data provider
-
Risk modeler
-
Technical vulnerability expert
-
Local planner
| Use case description | |
|---|---|
Name |
Life cycle of natural risk analysis in France |
Priority |
High |
Description |
An example based upon how it is understood by TWG NZ. National Risk Modelling is carried out. |
Pre-condition |
|
Flow of events – Basic path |
Hazard area definition |
Step 1 |
The topographical, environmental and other data providers spread all kind of data |
Step 2 |
The hazard modeler uses a methodology to define hazard areas |
Step 3 |
The hazard modeler discovers and gets external data, and uses them as a source for hazard area definition |
Step 4 |
The hazard modeler applies the methodology, and produces hazard areas |
Data source: name |
BDTOPO (Elevation model), Meteorological data, Geologic data, soil data, etc. |
Delivery |
Hazard areas |
Flow of events – Basic path |
Exposed elements analysis |
Step 5 |
The topographical, environmental and other data providers provide all kinds of data |
Step 6 |
The risk modeler uses a methodology to define risk zones |
Step 7 |
The risk modeler gets the hazard areas produced |
Step 8 |
According to the types of hazard areas he is working on, the risk modeler selects low-scale environmental data or topographical data that he considers as being exposed elements to the hazard area (the methodology previously given details the general types of elements of interest to be analysed) |
Data source: name |
BDTOPO (buildings, road networks, industrial facilities, census data, forests, monuments… |
Delivery |
Exposed elements |
Flow of events – Alternative path |
The risk modeler makes a vulnerability calculation |
Step 8 -a |
The risk modeler uses a methodology to calculate vulnerability |
Step 8 – b |
The risk modeler calculates the vulnerability for exposed territories. |
Step 8 -c |
The risk modeler can also ask for a technical expert to make an assessment of vulnerability of buildings, infrastructures, communities, people, etc, to a given hazard. |
Step 8 - d |
The risk modeler produces the vulnerability values |
Data source: name |
Exposed territories, Exposed elements, Hazard areas |
Delivery |
Vulnerability values |
Flow of events – Basic path |
Risk zones definition |
Step 9 |
The risk modeler produces the risk zones |
Step 10 |
The risk modeler completes the metadata of risk zones with the name of databases he used as sources (hazard areas, environment low-scale data, topographical data, etc) |
Step 11 |
The risk modeler produces the risk zones |
Delivery |
Risk zones |
Flow of events – Alternative path |
The risk modeler monitors the hazard area |
Step 11 –a |
The risk modeler monitors the hazard area with environmental monitoring facilities |
Flow of events – Basic path |
Risk analysis at local level |
Step 12 |
The local land-use planner obtains the risk zones |
Step 13 |
The local land-use planner overlays the risk zones with the source databases quoted in the Metadata |
Step 14 |
The local land-use planner overlays the risk zones with his database of topographical data. These data may be more accurate than the ones used by the risk manager, and are likely to be more up-to-date. |
Delivery |
Exposed elements |
Flow of events – Alternative path |
The land-use planner calculates vulnerability at a local level |
Step 14 – a |
The local land-use planner sharpens the vulnerability of his territory with high-scale topographical data to the hazard area. |
Delivery |
Vulnerability values |
Flow of events – Basic path |
Use of risk zones analysis at the local level |
Step 15 |
The local decision-makers use these analyses as input for risk mitigation (consolidation of buildings, construction of embankments, public awareness, reforestation, implementing local development plans, implementing deterrent measures, implementing insurance/reassurance measures). |
Step 16 |
The local decision-makers use these analyses as input for risk disaster management (creation of crisis management plans) |
Data source: name |
Environmental facilities, Land-Use data, risk zones |
Flow of events – Alternative path |
The land-use planner monitors the hazard |
Step 17 |
The local land-use planner monitors the hazard area with environmental monitoring facilities |
B.4. Forest Fires
Introduction
Forest fires are a major concern especially for southern Member States of the EU. As reported by the European Forest Fire Information System (EFFIS) an average of 70 000 fires take place every year burning more than half a million hectares in Europe. Although no clear trend regarding the areas burnt by forest fires could be detected in the last decades, fire events show increased intensity and impacts with a high number of fatalities and large economic losses. To address the increasing risks of forest fires, forest fire management has been improved in an integrated way. Thereby, a particular focus is being placed on forest fire prevention measures.
Specific forest fire policies exist in most EU Member States, but a harmonisation of these policies at the European level has not yet been achieved. At EU level a first regulation on forest fire prevention was issued in 1992. Since then several European initiatives have taken place. The European Commission has developed since 1998 the European Forest Fire Information System (EFFIS) which includes a module for forecasting and assessing the risks of forest fire at European level. The EFFIS[22] established by the Joint Research Centre and the Directorate General for Environment, is the EU focal point for information on forest fires addressing fire prevention, fire fighting and post fire evaluations. The wide range of available data and models covers among others fire danger forecast, fire emission and fire damage assessment, post-fire vegetation recovery.
In the last years the Commission put forest fires higher on the political agenda, focusing not only on fire fighting but also on prevention and adapting forest management to climate change. In these fields, preparatory work on two Council conclusions was carried out, the Commission adopted the Green Paper on forest protection and information and the European Parliament took initiatives in forest fire prevention. Furthermore the Commission supported the setting-up of the EU Forest Fires Tactical Reserve (EUFFTR), which aims at stepping up Member States cooperation to reinforce the overall EU fire-fighting capacity.
Overview and involved actors
There is lack of consensus in the literature on the meaning of the term "forest fire risk". Allgöwer et al. (2003) identified two main approaches to this term. First, the "wildland fire community" has defined fire risk by looking at the chances of having a fire event. For instance, FAO[23] defines forest fire risk as "the probability of fire initiation due to the presence and activity of a causative agent". This approach neglect the outcome (damage potential) of a possible fire event (Allgöwer et al., 2003; Chuvieco et al., 2010). Second, the "structural fire community" has implemented a fire risk approach that is more in line with the approach followed in other natural hazards, where risk is a function of probability of occurrence and consequence. In this document we follow the second approach because of its comprehensiveness and the inclusion of the two main components of forest fire risk: fire danger and vulnerability. Within this approach fire risk is the probability of a fire to happen and its consequences, fire danger considers the potential that a fire ignites and propagates, and vulnerability relates to the potential damage caused by the fire. It is noteworthy that the term exposure is not common in the forest fire literature. Being not exhaustive the table below illustrates the terminology used in the Forest Fires Use Case and compares it with the terminology adopted in Chapter 2 by TWG NZ. Figure 2 shows the framework adopted in this document and the interlinks between the factors of forest fire risk.
| Data Specification on Natural Risk Zones | Forest Fires Use Case |
|---|---|
Hazard: A dangerous phenomenon, substance, human activity or condition that may cause loss of life, injury or other health impacts, property damage, loss of livelihoods and services, social and economic disruption, or environmental damage. |
Forest fire danger can be defined as the probability that a fire with a given intensity ignites and propagates. |
Exposure: People, property, systems, or other elements present in hazard zones that are thereby subject to potential losses. |
Forest fire vulnerability is a notion referring to potential fire damage and impact. Hence, within the approach adopted in this Use Case, the vulnerability factor assesses potential damage and impact caused by the fire. |
Vulnerability: The characteristics and circumstances of a community, system or asset that make it susceptible to the damaging effects of a hazard. |
|
Risk: the combination of the consequences of an event (hazard) and the associated likelihood/probability of its occurrence. |
Forest fire risk is a function of probability of occurrence and consequence. |
In addition to the general conceptual framework, there are several perspectives from which forest fire risk assessments can be addressed. From the time-scale of the factors included in the assessment, fire risk can be classified into long-term and short term (San-Miguel-Ayanz et al., 2003). Long-term indices are based on variables that change relatively little in the short to medium term (e.g. topography, fuel). This type of assessment is useful for supporting management procedures such as long-term sustainable land management, rural planning, fire prevention and preparation of fire fighting strategies. Short term fire risk indices are based on variables that change nearly continuously over time, such as weather conditions. They are usually operationally implemented for early warning and preparedness support.
This use case describes the process for setting up the geographic data relevant for assessing forest fires risk (Figure 2). The modelling aspects behind fire danger, vulnerability or risk are out of the scope of the use cases in this document.
Figure 2: Forest fire risk analysis framework. Source: Allgöwer et al. (2003).
Figure 3: Forest fires use case diagram.
B.4.1. Forest fires danger mapping
Narrative description
Forest fire danger can be defined as the probability that a fire with a given intensity ignites and propagates. Hence fire danger is a function of ignition danger and propagation danger. The two main causes of ignition i.e. human and natural, and the moisture content of plants are considered for assessing ignition danger. Propagation danger is dealt with assessing fire spread potential, which is the result of fuel properties and amount, terrain characteristics and weather conditions, including strong winds that may exacerbate fire propagation.
The approach is well addressed for short-term systems. Long-term risk assessments would need to incorporate climatic data for assessing the long-term spatial-temporal setting that facilitates ignition and propagation.
Most short-term fire early warning systems assess fire danger using numerical indices not producing a probability per se. An example of this approach is the Fire Weather Index (FWI) system from the Canadian Forest Service[24]. The Canadian FWI consists of six components that account for the effects of fuel moisture and wind on fire behaviour. This is the approach adopted in EFFIS fire danger module. Short term fire danger rating systems are included in Figure 2 under the "Fire Danger Rating" box. These indices are commonly used by forest services and civil protection services in charge of fire prevention and fighting.
For assessing ignition danger several georreferenced datasets can be used (depending on the model):
-
Forest fire occurrence (human and natural) georreferenced time-series
-
Fuel moisture content - moisture content of vegetation (live and dead components): usually from remotely sensed imagery
-
Infrastructure (transport networks, electric lines, hotels, camp sites, etc)
-
Land use/land cover, urban/wildland interface
-
Population density and/or other relevant census data
-
Lighting occurrence
-
Climate or bio-climate datasets
-
Terrain (DEM)
-
Meteorological datasets (temperature, relative humidity, wind, rain)
For assessing propagation danger several georreferenced datasets can be used (depending on the model):
-
Fuel types
-
Fuel moisture content (live and dead component)
-
Meteorological datasets (temperature, relative humidity, wind, rain)
-
Terrain (DEM)
-
Forest fire mitigative measures (e.g. fire breaks)
This use case describes the main data needed for preparing forest fire danger maps either for short-term or long-term assessments. Notice that this is a live document resulting from a wide literature review and attempts to be as comprehensive as possible. However it could be the case that some specific approaches or methods are not included here.
Detailed description
| Use case description | |
|---|---|
Name |
Accessing data to assess forest fire danger |
Priority |
|
Description |
The user selects a geographic area and a search for relevant forest fire danger data is conducted |
Pre-condition |
Relevant forest fire danger data is available for the selected area |
Flow of events – Basic path |
|
Step 1 |
The user selects the area of interest and searches in a metadata catalogue for relevant data (topography, meteorological, climatic, fuel, vegetation…) |
Step 2 |
The user accesses the requested data and downloads it |
Step 3 |
When needed, downloaded data is processed to obtain derived information (fuel type from vegetation or aspect from DEM, for instance) |
Step 4 |
The user matches original and derived data to produce danger zones |
Flow of events – Alternative path |
|
Post-conditions |
|
Post-condition |
Forest fire danger zones map is achieved |
Description |
|
Data provider |
Each Member State |
Geographic scope |
All EU Member States, with appropriate cross border cooperation where necessary |
Thematic scope |
Natural Risk Zones (Forest fires) |
Scale, resolution |
Scale relevant to the application: from local/regional to continental (tbd) |
Delivery |
|
Documentation |
|
Requirements from the use case
The analysis of the use case indicates that it would be necessary to provide, at least, the following objects and attributes:
-
Forest fires occurrence (georreferenced time-series) and causes (human and natural)
-
Number of fires
-
Burnt area
-
Fuel data
-
Fuel moisture content - moisture content of vegetation (live and dead components)
-
Fuel types
-
Topographic data from DEM
-
Slope and aspect
-
Infrastructure and land use/cover
-
Transport networks, electric lines, hotels, camp sites, etc
-
Land use/land cover, urban/wildland interface
-
Population density and census data
-
Climate and meteorological datasets
-
Lighting occurrence
-
Climate datasets (temperature, relative humidity, wind, rain) or bio-climate dataset
-
Meteorological datasets (temperature, relative humidity, wind, rain)
B.4.2. Forest fire vulnerability mapping
Narrative description
Forest fire vulnerability is a notion referring to potential fire damage and impact. Hence, within the approach adopted in this use case, the vulnerability factor assesses potential damage and impact caused by the fire. For example, negative effects of fire have been classified in Chuvieco et al. (2010) in three main aspects:
-
Socio-economic values (properties, wood resources, recreational value, carbon stocks, etc)
-
Environmental degradation potential (soil erosion, vegetation conditions/vulnerability), and
-
Landscape value (uniqueness, conservation status, legal protection, etc).
This use case describes how these datasets can be accessed so that a vulnerability map could be derived from them.
Detailed description
| Use case description | |
|---|---|
Name |
Accessing data to assess vulnerability to forest fires |
Priority |
|
Description |
The user selects a geographic area and a search for relevant vulnerability data is conducted |
Pre-condition |
Relevant vulnerability data is available for the selected area |
Flow of events – Basic path |
|
Step 1 |
The user selects the area of interest and searches in a metadata catalogue for relevant data |
Step 2 |
The user accesses the requested data and downloads it |
Step 3 |
When needed, downloaded data is reclassified to obtain derived information |
Step 4 |
The user matches original and derived data to produce a vulnerability zones map |
Post-conditions |
|
Post-condition |
Forest fires vulnerability map is achieved |
Description |
|
Data provider |
Each Member State |
Geographic scope |
All EU Member States, with appropriate cross border cooperation where necessary |
Thematic scope |
Natural Risk Zones (forest fires) |
Scale, resolution |
Scale relevant to the application: from local/regional to continental (tbd) |
Delivery |
|
Documentation |
|
Requirements from the use case
The analysis of this use case shows that many datasets used for vulnerability mapping are the result of external models to the forest fire risk assessment. For instance, soil erosion potential is usually implemented using the Universal Soil Loss Equation (ULSE) approach. Tangible resources are usually evaluated using direct methods such as market price (e.g. wood resources). And intangible resources (recreational value) are usually evaluated using indirect methods such as travel-cost methods or contingency value methods. Therefore, considering the large number of methods and models usually involved in the implementation of forest fire vulnerability maps, in this section we provide a non-comprehensive general overview of the main datasets used in some operational systems (e.g. Chuvieco et al., 2010):
-
Economic values
-
Properties (value of properties)
-
Infrastructures and its value (buildings, housing, transport networks, distribution networks, utilities, land use, other infrastructures)
-
Wood resources (market value per ha)
-
Recreational value of forested areas (economic value per ha/year)
-
Carbon stocks (market value)
-
Environmental degradation potential (index)
-
Soil erosion (e.g. ULSE approach)
-
Vegetation conditions/vulnerability
-
Landscape value (economic value e.g. Euro/ha/year from indirect valuation methods)
-
Uniqueness
-
Conservation status
-
Legal protection
-
Etc.
B.4.3. Forest fire risk mapping
Narrative description
Forest fire risk is a function of probability of occurrence and consequence. Hence fire risk is the outcome of the assessment as shown in Figure 3. The integration of the fire danger factor (ignition and propagation potential) and the vulnerability factor (potential damage) may follow different approaches/methods and thus the resulting risk map can be represented using different configurations. The ideal model would follow a probabilistic approach in which for each place the probability of occurrence and severity of the fire is related with the potential consequence of fire. However, the large amount of data and techniques needed for implementing a probabilistic approach limits their operational implementation. Therefore often forest fire risk is represented in a qualitative scale from low or very low to high or very high fire risk.
The implementation of this use case follows the results of the previous use cases on fire danger and vulnerability. Hence we show briefly how fire danger and vulnerability data is accessed for implementing forest fires risk.
Detailed description
| Use case description | |
|---|---|
Name |
Accessing data to assess forest fires risk |
Priority |
|
Description |
The user selects a geographic area and searches for fire danger and fire vulnerability maps, then integrates the maps in an forest fire risk map |
Pre-condition |
Danger and vulnerability maps are available for the selected area |
Flow of events – Basic path |
|
Step 1 |
The user selects the area of interest and searches in a metadata catalogue fire danger and fire vulnerability maps |
Step 2 |
The user defines methods for integrating danger and vulnerability maps into a forest fire risk map |
Step 3 |
The user produces a forest fires risk map (short or long-term) |
Post-conditions |
|
Post-condition |
A forest fires risk map is produced |
Description |
|
Data provider |
Each Member State |
Geographic scope |
All EU Member States, with appropriate cross border cooperation where necessary |
Thematic scope |
Natural Risk Zones (forest fires) |
Scale, resolution |
Scale relevant to the application: from local/regional to continental (tbd) |
Delivery |
|
Documentation |
|
Requirements from the use case
The analysis of the use case shows that there is a need to provide the following objects and attributes for forest fire risk assessment:
-
Forest fire danger
-
Forest fires vulnerability
References
-
Allgöwer, B., Carlson, J.D. and van Wagtendonk, J.W., 2003. Introduction to Fire Danger Rating and Remote Sensing — Will Remote Sensing Enhance Wildland Fire Danger Rating? In: E. Chuvieco (Editor), Wildland fire danger estimation and mapping - The Role of Remote Sensing Data. Series in Remote Sensing. World Scientific Publishing, Singapore, pp. 1-19.
-
Chuvieco, E. et al., 2010. Development of a framework for fire risk assessment using remote sensing and geographic information system technologies. Ecological Modelling, 221(1): 46-58.
-
FAO, 1986. Wildland Fire Management Terminology. FAO Forestry Paper n. 70, p. 257.
-
San-Miguel-Ayanz, J. et al., 2003. Current methods to assess fire danger potential. In: E. Chuvieco (Editor), Wildland fire danger estimation and mapping - The Role of Remote Sensing Data. Series in Remote Sensing. World Scientific Publishing, Singapore, pp. 22-61.
B.5. Landslides
Currently a number of different landslide inventories exist in various databases and each uniquely addresses a specific purpose (for example we refer here to CSIRO https://www.seegrid.csiro.au/ twiki/bin/view/Geohazards/LandSlides, or http://www.landslides.usgs.gov among others). These databases range in scale and detail, and although some similarities and a number of common themes are apparent between databases, the method in which information is organised and described varies considerably. This means information cannot readily be compared or aggregated with other sources. Furthermore, these inventories are generally only accessible to a small number of individuals and subsequently, it is possible there is significant duplication of effort among landslide researchers independently attempting to fill information gaps. Landslide inventories are fundamental for developing rigorous hazard and risk assessments.
This is only an example of use case description, to show what it is, the link with examples of use, and what the impact is on the data model
B.5.1. Landslide hazard mapping
The hazard is often defined as the probability of occurrence of a potentially damaging phenomenon of a given intensity within a given area and a given period of time. To define this probability the geologist or engineer has to access datasets of observed past events, climate, lithology, earthquake activity, and topography, physical, chemical, mechanical properties of rocks or soils, hydrological, hydrogeological data etc.
Among various landslide types (i.e. slides, rockfalls, rock flows, debris flows, earth flows, etc), the rapid, and long run-out landslides, especially those that occur in urbanizing areas often cause catastrophic damage to the community.
The goal of this use case is to deliver historical and possible future occurrence of a landslide in a given area for the creation of appropriate landslide risk preparedness plans. Interoperability will enable landslide information to be accessed in real time by all levels of government, geotechnical professionals, emergency managers, land use planners, academics and the general public regardless of where it is hosted. It provides direct access to spatial-enabled data and allows users to simultaneously search and query the most up-to-date information available in geographically distributed databases through a single website. The search results can be displayed as reports, graphs, maps, statistics or tables, and data can be queried against background datasets, such as topography, geology and geomorphology.
Actors:
-
Geological surveys to provide geological information (Geological Surveys represent the Member States)
-
Engineers responsible for establishing hazard and risk area maps using the geological information in combination with other data.
-
Authorities for managing appropriate landslide risk preparedness plans.
-
geotechnical professionals,
-
emergency managers,
-
land use planners,
-
academics, and
-
the general public.
Narrative description
Landslides are various types of gravitational mass movements of the Earth’s surface that pose the Earth-system at risk. A classification of landslides according to material type (i.e. rock, soil, debris) and type of movement (i.e. rock falls, topples, slides, spreads, rock flows, debris flows, earth flows and combinatorial or complex slides) is schematically shown in Fig. 4.
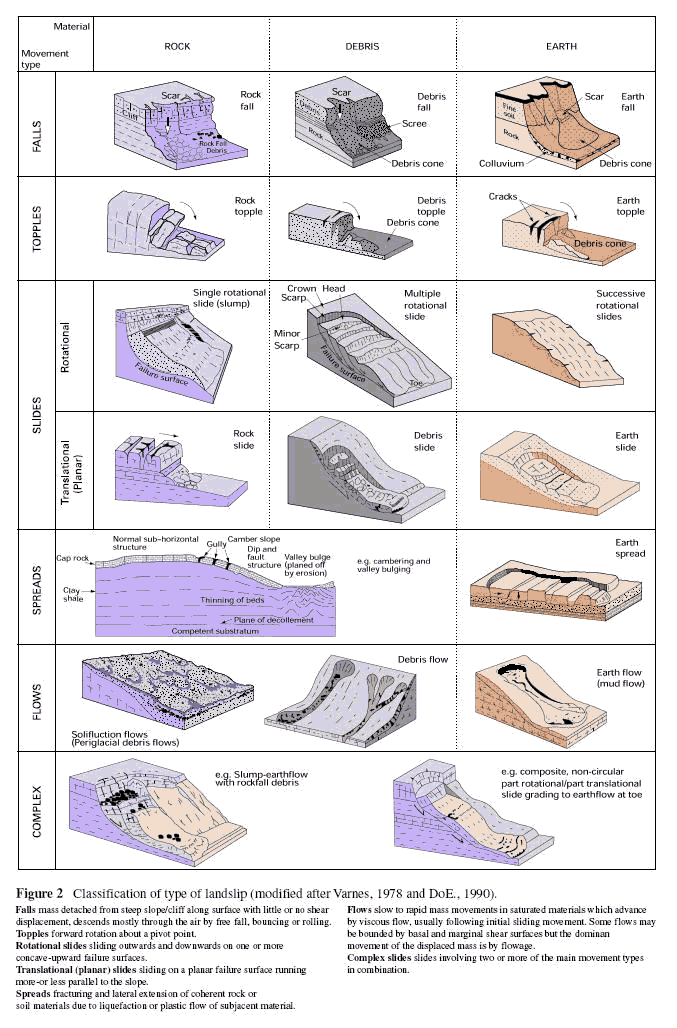
Figure 4: Classification of type of landslides occurring in rocks, debris or soil masses (http://www.geonet.org.nz/landslide/glossary.html).
"Landslides" are a complex-disaster phenomenon triggered by earthquakes, heavy rainfall (typhoons, hurricanes), sustained rainfall, volcanic eruptions and heavy snowmelt, unregulated anthropogenic development, mining, tunnelling and others. Landslides cause many deaths and injuries and great economic loss to society by destroying buildings, roads, life lines and other infrastructures; they also pose irrecoverable damage to our cultural and natural heritage. Large and small landslides occur almost every year in nearly all regions of the world. Large-scale coastal or marine landslides are known to cause tsunami waves that kill many people. Also large-scale landslides on volcanoes can dislocate the mountain tops and trigger volcanic eruptions. Landslides also may occur without earthquakes, heavy rains, volcanic eruptions, or human activities due to progress of natural weathering; therefore, they occur almost everywhere in the world. Landslides most commonly impact residents living on and around slopes.
Landslides are a natural phenomenon which can only be effectively studied in an integrated, multidisciplinary fashion, including contribution from different natural and engineering sciences (earth and water sciences), and different social sciences. This is also the case because landslides are strongly related to cultural heritage and the environment.
Landslides should be jointly managed by cooperation of different ministries and departments of government including some representing education, science and technology, construction and transportation, agriculture, forestry, and the environment, culture and vulnerable groups (the poor, aged, handicapped, or children). As landslides are highly localized phenomena it is crucial to seek the contribution of local governments or autonomous communities.
The disasters caused by landslides are of a very complex nature wherever they occur around the world. Landslide risk preparedness is to be managed by multi-ministries.
The socio-economic impact of landslides is underestimated because landslides are usually not separated from other natural hazard triggers, such as extreme precipitation, earthquakes or floods. This underestimation contributes to reducing the awareness and concern of both authorities and general public about landslide risk.
Landslide inventories are fundamental for developing rigorous hazard, vulnerability and risk assessments. However, an agreed, systematic way of developing these inventories is presently not available, neither is there an example of 'best practise' that could be used as a guideline in EU.
Detailed description
| Use case description | |
|---|---|
Name |
Landslides |
Priority |
High |
Description |
The user selects the relevant geographic area and searches for historical landslide data (time of occurence, type, triggering factor, intensity or level (velocity, spread, deposition height, runout extent etc), geomorphological (e.g. terrain gradient, deep channels), geological (including problematic soils also such as quick clay or other), geotechnical, vegetation coverage, precipitation, earthquake, monitoring data etc as well as existing data for future landslide occurrences and likelihood of occurence. |
Pre-condition |
Landslide data are available in line with INSPIRE specifications. A specific vocabulary related to the user requirements is available with a "mapping" between all relevant landslide description terms and user’s terms. |
Flow of events – Basic path |
Hazard area definition |
Step 1a |
The user selects the area of interest and searches in a metadata catalogue for past landslide maps, as well as hazard area maps. |
Step 2a |
The user displays the landslides historical and future hazard area map and accesses detailed information. |
Step 3a |
|
Deliverable |
Hazard area map |
Flow of events – Alternative path |
Hazard area map creation |
Step 1b |
The user may use his/her own models to create a landslide hazard area map based on accessed information as above and compare model results with possible already available hazard area maps. |
Step 2b |
The hazard modeler selects the most appropriate methodology to delineate hazard areas. For example according to type of landslide i.e. rock slope, or topples or flows in contrast to debris flows etc, and according to the approach i.e. empirical, semi-empirical, analytical or numerical methods. It is noted that the hazard area includes the possible runout spread of the landslide based on appropriate tools for dynamic analysis of landslides. |
Step 3b |
The user sets the appropriate criteria for delineation of hazard areas. For example, for "debris flows" sets criteria as follows:
|
Step 4b |
The hazard modeler searches and gets external data and relevant thematic maps according to the criteria set above, such as 1) geomorphological, 2) geological, 3) structural geological, 4) geotechnical & monitoring data, 4) drainage, 5) catchment areas, 6) precipitation, 7) nearby activities that may trigger landslides such as tunneling, mining or large excavations, 8) earthquake activity with characteristic accelerations, 9) land-use, and subsequently use them as a source for hazard area delineation. |
Step 5b |
The hazard modeler applies the chosen methodology, and produces hazard areas. |
Deliverable |
A landslide hazard area map which identifies areas of differing landslide potential (probability of occurence) may be generated. Hazard area map (line for trajectories of rock-falls, polygons, vectors for landslide flow displays, or Digital Terrain Model DTM hazard zone maps). |
Post-conditions |
|
Post-condition |
The user has a set of data and predictions related to the landslide occurrence potential of the selected area. |
Description |
Landslide historical data from national sources. |
Data provider |
Each Member State |
Geographic scope |
All EU Member States, with appropriate cross border cooperation where necessary |
Thematic scope |
Natural Risk Zones (Landslides) |
Scale, resolution |
Scale relevant to the application (tbd) |
Delivery |
Relevant INSPIRE compliant service |
Documentation |
Document reference for Landslide hazard definition. |
Requirements from the use case
Analyzing the use case, there is a need to provide the following objects and attributes:
-
Geological units with:
-
their related polygons
-
lithological descpription of each geological unit
Geological faults with:
-
their surfaces in 3D space
-
type of fault: normal, thrust, strike-slip
-
attribute: active or non-active
Borehole data with:
-
geologic unit thickness and depth
-
water level
-
any other properties (physical and chemical) measured
Geotechnical data with:
-
physical, chemical and engineering data related to the geological units (from measurements: porosity, grain size, permeability, compressibility etc)
Monitoring data:
-
Type of monitoring instrumentation
-
Location of sampling measurements
-
Type and record of measurements
Landslide past record:
-
Activity State
-
Last Recorded Occurrence Time
-
Recurrences
-
Representative Location
-
Shape
-
Total Volume
-
Typical Movement Type
Landslip Event:
-
Volume
-
Causative Factor
-
Movement Type
-
Triggering Factor
Damage Assesment Report:
-
Reported Cost
-
Affected Entity Type
-
Number Affected
-
Report Date
-
Damage Type
-
Severity Code
B.5.2. Landslide vulnerability assessment
Narrative description
The aim is the vulnerability (damage) assessment against landslides, considering human life, land resources, structures, infrastructure, and cultural heritage.
| Use case description | |
|---|---|
Name |
Landslides |
Priority |
High |
Description |
The user selects the relevant geographic area and searches for historical landslide data, terrain, geological, geotechnical and monitoring data as well as hazard and risk analysis data for future landslide occurrences. |
Pre-condition |
Landslide data are available in line with INSPIRE specifications. A specific vocabulary related to the user requirements is available with a "mapping" between all relevant landslide description terms and user’s terms. |
Flow of events – Basic path |
|
Step 1 |
The risk modeler gets data on population (number or density, sex, age etc), utility networks (type, capacity), transportation networks (roads, railroads, tunnels, bridges), industrial facilities, buildings (type of structure and occupation), forests, monuments, industrial infrastructure, tourism facilities, services facilties (number and types of health, educational, cultural and sport facilities) that he/she considers as being exposed elements to the given landslide hazard area. |
Deliverable |
Exposed elements |
Step 2 |
The risk modeler selects a robust methodology to calculate vulnerability of a given exposed element under a given landslide intensity. Intensity of a landslide expresses the destructiveness of the landslide and may be described by velocity, kinetic energy, momentum, flow discharge, total displacement. |
Step 3 |
The risk modeler calculates the vulnerability for exposed elements under a given landslide intensity. |
Deliverable |
Vulnerability or damage calculations for each exposed element at each given landslide scenario (intensity). |
Flow of events – Alternative path |
|
Post-conditions |
|
Post-condition |
The user has a set of data and predictions related to the landslide occurrence potential of the selected area. |
Description |
Landslide historical data from national sources. |
Data provider |
Each Member State |
Geographic scope |
All EU Member States, with appropriate cross border cooperation where necessary |
Thematic scope |
Natural Risk Zones (Landslides) |
Scale, resolution |
Scale relevant to the application (tbd) |
Delivery |
Relevant INSPIRE compliant service |
Documentation |
Document reference for Landslide hazard definition. |
B.5.3. Landslide Risk assessment
Narrative description
As a consequence of climate change and increase in exposure in many parts of the world, the risk associated with landslides is growing. In areas with high demographic density, protection works often cannot be built because of economic or environmental constraints, and is it not always possible to evacuate people because of societal reasons. One needs to forecast the occurrence of landslide and the hazard and risk associated with them. Climate change, increased susceptibility of surface soil to instability, anthropogenic activities, growing urbanization, uncontrolled land-use and increased vulnerability of population and infrastructure as a result, contribute to the growing landslide risk. According to the European Union Strategy for Soil Protection (COM232/2006), landslides are one of the main eight threats to European soils. Also, as a consequence of climatic changes and potential global warming, an increase of landslide activity is expected in the future, due to increased rainfalls, changes of hydrological cycles, more extreme weather, concentrated rain within shorter periods of time, meteorological events followed by sea storms causing coastal erosion and melting of snow and of frozen soils in the Alpine regions. The growing hazard and risk, the need to protect people and property, the expected climate change and the reality for society to live with hazard and risk and the need to manage risk to set the agenda for the profession to assessing and mitigating landslide risk.
Risk assessment and communicating risk should be performed in an easily understood manner.
Detailed description
| Use case description | |
|---|---|
Name |
Landslides |
Priority |
High |
Description |
The user selects the relevant geographic area and searches for hazard zone and vulnerability data for future potential landslide occurrences. |
Pre-condition |
Hazard zone and vulnerability data are available in line with INSPIRE specifications. A specific vocabulary related to the user requirements is available with a "mapping" between all relevant landslide description terms and user’s terms. |
Flow of events – Basic path |
Risk zone delineation (e.g. Fig. 2) |
Step 1 |
The user selects the area of interest and searches in a metadata catalogue for hazard area maps and vulnerability data. |
Step 2 |
The user sets the criteria for risk mapping. |
Step 3 |
The user defines methods for integrating hazard area and vulnerability assessments into a landslide risk map |
Step 4 |
The user accesses detailed information. |
Step 5 |
The user may use his/her own models to create risk maps based on accessed information as above and compares model results with possible available risk maps. |
Deliverable |
The user produces a landslide risk zone map (short or long-term) |
Post-conditions |
|
Post-condition |
The user has a set of data and predictions related to the landslide risk zone map of the selected area. |
Description |
Landslide historical data from national sources. |
Data provider |
Each Member State |
Geographic scope |
All EU Member States, with appropriate cross border cooperation where necessary |
Thematic scope |
Natural Risk Zones (Landslides) |
Scale, resolution |
Scale relevant to the application (tbd) |
Delivery |
Relevant INSPIRE compliant service |
Documentation |
Document reference for Landslide hazard definition. |
Figure 5: Landslide risk zone map of Madeira, Portugal, http://www.zki.dlr.de/system/files/media/filefield/map/low/EUSC_20100222_Portugal_Madeira_lanslide_risk_a_low.jpg
{kind=link}
References:
Blaikie, P., Cannon, T., Davis, I., Wisner, B., 1994. At Risk: Natural Hazards, People’s Vulnerability, and Disasters. Routledge, New York.
Lee, E.M., Jones, K.C., 2004. Landslide Risk Assessment. Thomas Telford, London.
Phoon, K.-K., 2004. Risk and vulnerability for geohazards — vulnerability in relation to risk management of natural hazards. ICG Report 2004-2-3, Oslo.
Rashed, T., Weeks, J., 2003. Assessing vulnerability to earthquake hazards through spatial multi criteria analysis of urban areas. International Journal of Geographic
Information Science 17 (6), 547–576.
Fell, R., 1994. Landslide risk assessment and acceptable risk. Canadian Geotechnical Journal 31, 261 - 272.
B.6. Earthquake insurance
Narrative description
The building Code of European countries prepared a special earthquake Hazard map for the purpose of seismically resilient civil engineering and construction. An extensive study could be found in http://eurocodes.jrc.ec.europa.eu/doc/EUR23563EN.pdf:
"A review of the seismic hazard zone in national building codes in the context of Eurocode 8"
In this map, places with the key parameter- awaited maximal level of earthquake– peak ground acceleration in a given interval - is projected as an area of equal seismic hazard. The territory (of Bulgaria) is presented as set of multi-polygons, where each multi-polygon corresponds to some specific interval of peak ground acceleration/ awaited level of seismic reaction.
The Insurance implementation of this earthquake risk map is based on the following:
The reality is that a substantial number of existing dwellings (in some areas – more than 50%) are "pre code", i.e. are not resistant to potential maximal local seismic impact
Less than 20% of dwellings comply with the latest building code i.e. is constructed to be resistant to maximal awaited seismic phenomena for their territory.
The general insurance practice uses different tariffs for insurance premium calculation depending on the location of the insured building/property in the different zones of the earthquake hazard map from the building Code. The more strong seismic motion is expected – higher insurance premium is calculated. In addition, other key parameters, related to seismic resilience, such as Building material and Building height are also considered.
There is an unofficial exception for new buildings of less than 20 years (the new building code) for which the smallest seismic level tariff is applied indifferently of their location
Detailed description
Use case description |
|
Name |
Accessing data to assess potential earthquake damage |
Priority |
Medium |
Description |
The user selects a geographic area and search for relevant data on earthquake hazard. After that the user searches for relevant construction related data on buildings, Installations or any assets to be insured |
Pre-condition |
Relevant earthquake hazard data is available for the selected area, et least in the volume available from (doc 1) |
Flow of events - Basic path |
|
|---|---|
Step 1 |
The user selects the area of interest and searches in metadata catalogues for the relevant data (Hazard , assets specific parameters) |
Step 2 |
The user accesses the relevant data and downloads the necessary portion on the target object of interest |
Step 3 |
The user calculates the risk coefficient and determines the risk premium for the requested risk cover |
Description |
|
Data provider |
Each member State |
Geographic scope |
All EU Member States |
Thematic scope |
|
Scale, resolution |
Scale relevant to the application, requiring at least any village position in the earthquake hazard map |
Delivery |
|
Documentation |
|
Requirements from the use case
Analysing the use case, there is a need to provide the following objects and attributes:
-
Earthquake hazard map
-
Hazard repeating period (50, 475, 1000 years) eg.
-
anticipated peak ground acceleration
-
Information on geological faults if any (for utility infrastructure, transport infrastructure)
-
Buildings, Production and industrial facilities
-
Type of construction (material)
-
Year of construction (applied anti-seismic Code)
-
height of construction
-
Utility infrastructure
-
Type of infrastructure (e.g. pipeline, underground cable etc)
-
Type of construction (material)
-
Year of construction (applied anti-seismic Code)
-
height of construction
Annex C: Code list value - (normative)
INSPIRE Application Schema 'NaturalRiskZones'
| Code List |
|---|
ExposedElementCategoryValue |
NaturalHazardCategoryValue |
ExposedElementCategoryValue
|
NaturalHazardCategoryValue
|
Annex D: The Natural Risk Zones extension for Floods Directive - (informative)
Based on the relevant expertise in the Natural Risk Zones thematic working group (TWG NZ) and valid collaboration with relevant Floods Directive (FD) group the team decided to elaborate, as a example, an extension of the NaturalRiskZones data model to address the Floods Directive specific requirements.
Description and explanation:
The model for Floods ("Floods_Example_Model" – figure 1) is an illustrative example demonstrating how the core Natural Risk Zones data model could be extended for a specific hazard category – in this case "Flood" - by a data provider.
At this time, Flood is the only hazard category with a Directive (2007/60/EC, so called "Floods Directive", subsequently abbreviated to "FD") which requires Member States to provide information about past flood events and their adverse consequences for specific objects, flood hazard and flood risk with associated spatial data. The development of reporting interfaces for FD-reporting requirements was/is part of a process which proceeded in parallel to the development of this data specification and is still on-going. The team is in collaboration with the Working Group Floods Drafting Group to ensure consistency between FD reporting requirements and the Natural Risk Zone Data Specification. The constraints shown in the Flood_Example_Model reflect requirements which are agreed between MS and EU-Commission and therefore are mentioned in Reporting Sheets of the Floods Directive. Please note that this extension of the NRZ Core model is not a premature fixing in terms of FD-reporting but TWG NZ have been careful to integrate the contents of the requirements of FD and also candidate types from the INSPIRE Annex I theme Hydrography as far as possible.
TWG NZ believes that the NZ core spatial object types definitions give enough flexibility to data providers for the purposes of modelling FD spatial information to support flood data providers with a floods specific extension which can be re-used and modified.
It is important to recognise that it has not been possible to provide the generally accepted "flood types" (with regard to definition nor description). Therefore, further specification of this example model may be necessary by data providers for example by using the "list of flood types" which was developed for Floods Directive-reporting. It was recognised that data providers, other than those reporting for the "Floods_Example_Model", the team considered all spatial object components which are relevant for different steps of implementing FD but modelled the links between single components of the model voidable.
For the first stage of the FD reporting cycle (left-hand side in model: "PreliminaryFRAssessment") the team assumes that a Preliminary Flood Risk Assessment could be carried out in areas for which it is known are prone to inundation (as feature type "InundatedLand" and InundationValue were modelled in Annex I by TWG Hydrography). Due to this "PreliminaryFRAssessment" as a data type contains the feature type "InundatedLand" or to view it another way around "InundatedLand" could be one component of a "PreliminaryFRAssessment". The team also assumes that knowledge about inundation prone areas is derived from (documented) observation of flood events ("ObservedEvent") that have happened in the recent past (in FD terminology = "past flood events"). An observed event that is worthy of being documented with an extent is commonly named (e.g. fictionally "flood of Paris 1998") but not necessarily ("nameOfEvent" therefore is voidable). When an event is observed, it is usually known when its occurrence starts ("validFrom") and ends ("validTo"); "validFrom" matches with the FD-requirement to provide information about "DateOfCommencement" while the time gap between "validFrom" and "validTo" matches with FD-requirement "duration". To reflect FD-requirements with regard to different scenarios addressed by "Recurrence" respectively "Frequency" (remark: in other context, terms like "return period" or "probability" are used), the team included additionally "likelihoodOfOccurrence" and for the expression of related measurable/quantifiable characteristics "magnitudeOrIntensity" as voidable attributes. It was further noted that an "ObservedEvent" is not always an area (a polygon); therefore, the geometry is "GM_Object" which allows a user to provide any kind of geometry type. This enables data providers to deliver spatial information about historical (flood) events (for which precise extents are not available) by providing the most suitable geometry to represent the affected area (e. g. in some cases historical storm surges modified the shape of a coastal area substantially, therefore it is difficult to provide spatial information about the flood extent).
Another spatial object type for "PreliminaryFRAssessment" is "PotentialFloodedArea" as the result of the PreliminaryFloodRiskAssessment ("PotentialFloodedArea" represents FD-"Areas with potential significant flood risk") with its respective delineation of the spatial object type "AbstractHazardArea".
Using the spatial object type "PotentialFloodedAreaElement" the object is considered a component of "PotentialFloodedArea" as different flood scenarios (as mentioned in FD art. 6) are generally related to different flood extents and corresponding measurable/quantifiable characteristics and are essentially input for the preparation of FD_FloodHazardMap. This is additionally addressed by setting the constraints in the two upper NOTE-boxes in the diagram. Furthermore, "PotentialFloodedAreaElement" is required in considering that a potential flooded area as a result of modeling could be provided as vector geometry or coverage.
The second step in terms of FD-implementation also requires the preparation of Flood Risk Maps for the specific flood extents of each scenario as FD_Flood Hazard Maps are the basis for FD_FloodRiskMaps.
On the Flood Hazard Map "PotentialFloodedAreaElement" objects
The "PotentialFloodedArea" objects that are represented nn the Flood Risk Map, are the same that are represented on a flood hazard map. Upon the flood hazard map, the "PotentialFloodedAreaElements" that are associated to the potential flooded area are also represented.
The constraints in the upper NOTE-box belonging to "FD_FloodHazardMap" reflect the given possibility to limit scenarios for flooding due to groundwater or seawater to extreme event scenarios with a low probability).
The NOTE-box belonging to "FD_FloodRiskMap" reflects the FD-requirement to show "potential adverse consequences" for different subjects of protection which could occur in the case of flooding - and this for each flood scenario. FD requests that other factors are indicated, for example the "indicative number of inhabitants potentially affected", "type of economic activity of the area potentially affected" etc.
Because the NZ data specification has to represent all hazard/risk categories TWG NZ used "Exposed element" as a more neutral term. "Potential Adverse Consequences" and also "Adverse Consequences" (see below) respectively subjects of protection are represented in the Natural Risk Zones Core by the spatial object type "AbstractExposedElement" which could be specified in terms of floods by using the FD-list "adverse consequences". Specific "Exposed elements" are components of other INSPIRE data specifications.